
Network infrastructure maintenance is the structured set of preventive and corrective activities that keep routers, switches, firewalls, cabling, and cloud connectivity operating reliably. It covers hardware health checks, firmware updates, security audits, performance testing, and configuration management — all designed to prevent outages before they affect business operations.
Most unplanned network outages are not caused by sudden hardware failure. Research from the Uptime Institute consistently shows that human error and deferred maintenance account for the majority of avoidable downtime events. When organisations skip routine checks — firewall rule reviews, Wi-Fi coverage testing, log analysis — small faults accumulate until they trigger a disruption that halts productivity and carries real financial cost. A structured maintenance programme changes that equation: instead of reacting to failures, your team identifies degraded links, misconfigured rules, and rogue devices before they escalate. The result is a network that supports business continuity rather than threatening it.
Network Infrastructure Maintenance: scope and downtime prevention
Connectivity is not a background utility — it is the operational foundation on which every business process depends. Network infrastructure maintenance is the discipline that keeps that foundation stable, secure, and measurable. At Impulso Tecnológico, we frame maintenance as a continuous lifecycle rather than a reactive fix: from the physical layer of certified structured cabling through to logical configuration management and cloud service availability.
The table below contrasts a reactive approach with a structured preventive maintenance model across the dimensions that matter most to operations teams:
| Dimension | Reactive (no maintenance plan) | Preventive maintenance programme |
|---|---|---|
| Fault detection | After user impact is reported | Before service degradation reaches users |
| Downtime duration | Hours to days (diagnosis + fix) | Minutes to hours (known baseline + rapid response) |
| Security posture | Firewall rules accumulate unchecked | Regular firewall rule review and access validation |
| Documentation | Incomplete or outdated | Current, version-controlled, audit-ready |
| Cost profile | Unpredictable emergency spend | Controlled, budgeted maintenance cost |
| Compliance readiness | Gaps discovered during audits | Continuous evidence trail (logs, change records) |
With over 25 years of experience delivering IT managed services and structured cabling across Spain, Portugal, and 25 additional countries, Impulso Tecnológico has seen both sides of this table in practice. Organisations that invest in structured, preventive network maintenance consistently experience fewer disruptions and lower total incident cost.
What counts as network infrastructure (hardware, cabling, software, cloud)
Network infrastructure spans four interdependent layers, and maintenance must address all of them. The physical layer includes routers, switches, firewalls, access points, patch panels, and the structured cabling — categories 5e, 6, 7, and optical fibre — that connects them. The logical layer covers firmware, operating systems, VLAN configurations, routing tables, and firewall rule sets. The service layer includes DNS, DHCP, VPN gateways, and authentication services. Finally, the cloud layer encompasses Microsoft 365 tenants, Azure virtual networks, and any hybrid connectivity between on-premises and cloud environments. A maintenance programme that focuses only on hardware while ignoring configuration drift or cloud identity management will leave significant risk unaddressed. Effective network infrastructure maintenance treats all four layers as a single, interconnected ecosystem.
Why preventive maintenance reduces downtime and incident cost
Preventive maintenance works because it converts unknown risks into known, manageable items before they cause service loss. Continuous network monitoring and reporting surfaces anomalies — unusual traffic patterns, interface errors, latency spikes — that precede failures by hours or days. Scheduled firmware updates close known vulnerabilities before they are exploited. Regular log review identifies unauthorised access attempts and configuration changes that would otherwise go undetected. Early fault detection dramatically shortens mean time to resolution because engineers arrive with context rather than starting blind. The financial argument is straightforward: the cost of a structured monthly maintenance window is a fraction of the cost of an unplanned outage that halts operations, triggers SLA penalties, or results in a data breach. Preventive network maintenance is not an overhead — it is risk mitigation with a measurable return.
Maintenance outcomes: stability, safety, and maintainability
A well-executed maintenance programme delivers three measurable outcomes. Stability means the network operates within defined performance parameters — latency, packet loss, and throughput remain consistent and predictable. Safety means the security posture is continuously validated: firewall rules are reviewed, access controls reflect current staff roles, and VPN configurations meet current threat standards. Maintainability means the infrastructure is documented, organised, and accessible — abandoned cables are removed, racks are labelled, and configuration records are current. This third outcome is often underestimated: an unmaintainable network is expensive to troubleshoot and difficult to hand over to a new engineer or third-party provider. At Impulso Tecnológico, certified structured cabling installation and organised cabling management are built into our maintenance scope precisely because physical maintainability directly affects the speed and cost of every future intervention.

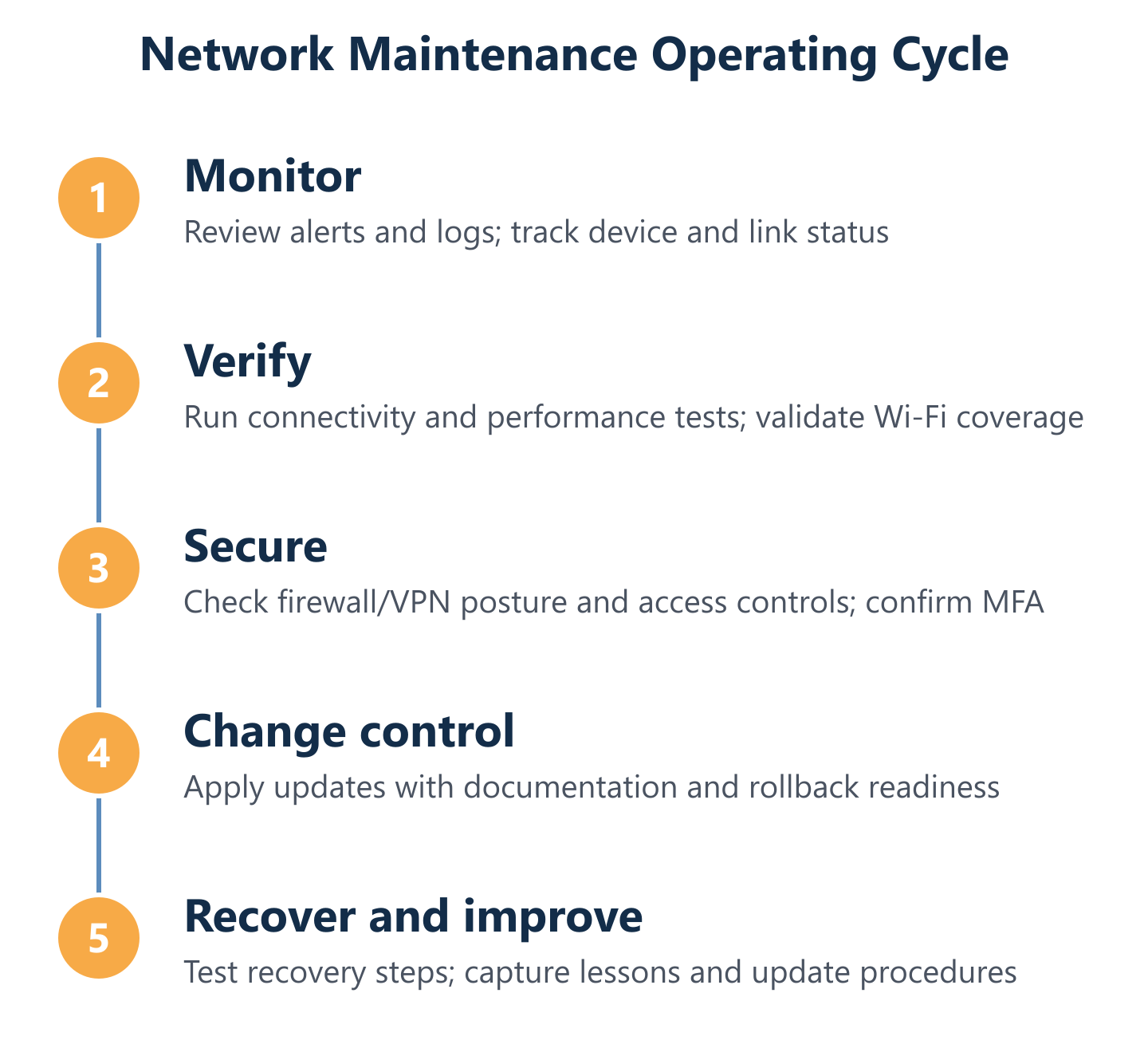
Core maintenance routines: daily, weekly, monthly checks
A maintenance programme without a defined cadence is just a list of intentions. The operational value comes from executing checks at the right frequency — catching fast-moving issues daily, verifying trends weekly, and performing deeper audits monthly. Impulso Tecnológico's managed services model structures this cadence around proactive monitoring and rapid response, with the physical infrastructure layer — certified structured cabling, organised racks, and clearly documented topology — providing the stable foundation that makes every check faster and more reliable.
The cadence works across three time horizons:
- Daily: Automated monitoring alerts for interface errors, device availability, and threshold breaches; review of critical security event logs.
- Weekly: Verification of monitoring alert history; inventory drift detection to identify new or removed devices; review of bandwidth utilisation trends and any anomalies flagged during the week.
- Monthly: Full firewall rule review; access control and user account validation; Wi-Fi coverage testing across all areas; firmware and patch status audit; connectivity and performance tests on key links; update of network documentation and change records.
This structure ensures that no layer of the network goes unexamined for more than 30 days, and that daily monitoring provides the early-warning data needed to make monthly audits efficient rather than exploratory.
Daily/weekly monitoring: alerts, log review, inventory drift detection
Daily network monitoring and reporting should be automated, with human review focused on actionable alerts rather than raw data. Network management platforms — whether on-premises or cloud-based — should be configured to alert on device unavailability, interface error rates exceeding defined thresholds, and unusual traffic volumes that may indicate a security event or hardware fault. Weekly checks add a layer of trend analysis: reviewing the alert history for the past seven days surfaces patterns that individual daily alerts might not reveal. Inventory drift detection — comparing the current list of connected devices against the approved baseline — is particularly valuable for identifying unauthorised devices or shadow IT additions that introduce both security and performance risks. Keeping this baseline current is a maintenance task in itself, and one that pays dividends during incident response.
Monthly network health checks: firewall rule review and access validation
Firewall rule sets are among the fastest-accumulating sources of technical debt in any network. Rules added for temporary projects, remote access during a specific period, or legacy applications frequently remain in place long after their purpose has expired — creating unnecessary attack surface. A monthly firewall rule review should systematically identify rules with no recent traffic, rules that overlap or contradict each other, and rules that grant broader access than the original requirement justified. Alongside firewall hygiene, monthly access validation checks that user accounts and role-based permissions reflect current staff — deactivating accounts for leavers, confirming MFA enforcement, and reviewing VPN access groups. These two tasks together address the most common vectors for both accidental misconfiguration and deliberate unauthorised access.
Connectivity and performance tests: wired links, Wi-Fi signal checks, speed consistency
Performance testing should be repeatable and location-specific. For wired infrastructure, monthly tests should measure latency and throughput on critical links — WAN connections, inter-site links, and server access paths — comparing results against the established baseline to detect gradual degradation before it becomes a user complaint. Wi-Fi coverage testing requires physical validation: walking the coverage area with a site survey tool to confirm signal strength, channel utilisation, and roaming behaviour meet the defined service standard. Organisations that skip Wi-Fi coverage testing typically discover coverage gaps only when a user reports a problem in a specific location. For structured cabling, Impulso Tecnológico's certification process provides the initial performance baseline; subsequent maintenance checks verify that the physical infrastructure continues to meet the original specification — particularly important after any building works or equipment moves.
Security, change control, and choosing a third-party maintenance provider
Security maintenance and change management are not separate disciplines from network infrastructure maintenance — they are integral to it. Every unreviewed firewall rule, every undocumented configuration change, and every unpatched firmware version is a maintenance failure with a security consequence. Impulso Tecnológico integrates security hardening directly into its managed IT support model, using technologies including Sophos, Fortinet, and Veeam to maintain consistent protection across the infrastructure lifecycle. The same principle applies to change management: a network that changes without a documented process is a network that will eventually fail in a way that is difficult and expensive to diagnose.
When evaluating a third-party network maintenance provider, the following criteria distinguish capable partners from those who simply respond to tickets:
- Structured reporting: Regular network monitoring and reporting with clear metrics, not just incident summaries.
- Defined maintenance windows: Scheduled, communicated windows that minimise business disruption.
- Proactive security integration: Firewall rule review, access control audits, and patch management built into the service — not offered as extras.
- Change management process: A documented approval and rollback procedure for all configuration changes.
- Compliance awareness: Familiarity with GDPR obligations relevant to network data handling and access logging.
- Physical and logical scope: Ability to cover both structured cabling maintenance and logical network configuration — reducing the handover gaps that slow down fault resolution.
- Clear SLA commitments: Response and resolution time targets that are contractually defined and measurable.
Security maintenance for networks: access control, VPNs, and firewall hygiene
Network security maintenance is a continuous process, not an annual audit. Firewall posture should be reviewed monthly at minimum, with any rule changes logged and justified. VPN configurations require particular attention: authentication methods, split-tunnelling policies, and certificate validity all degrade over time if not actively managed. Access control maintenance means ensuring that every user, device, and service account has only the permissions it currently requires — the principle of least privilege applied operationally rather than just at provisioning. Multi-factor authentication enforcement should be validated regularly, particularly after directory changes or new application integrations. Continuous log review provides the evidence trail that both supports incident response and satisfies GDPR requirements for demonstrating appropriate technical controls. Impulso Tecnológico's security stack — built around Fortinet and Sophos technologies — is maintained as part of its managed services model, ensuring that security hygiene is embedded in routine operations rather than treated as a separate workstream.
Change management and configuration hygiene to prevent misconfigurations
Configuration drift — the gradual divergence between documented and actual network state — is one of the most common causes of hard-to-diagnose network faults. It happens when changes are made without following a formal process: a firewall rule added in an emergency, a VLAN modified to resolve a connectivity complaint, a switch port reconfigured without updating the topology document. Over time, the gap between what the documentation says and what the network actually does becomes wide enough to cause outages during otherwise routine maintenance. Effective change management for network configurations requires a formal request and approval process, a pre-change backup of affected device configurations, a defined rollback procedure, and post-change documentation updates. This is not bureaucracy — it is the operational discipline that makes network resilience and recovery planning reliable rather than theoretical.
What to ask a third-party provider: reporting, maintenance windows, monitoring, compliance
Choosing a third-party network maintenance provider is a procurement decision with long-term operational consequences. Before signing, ask specifically: What does your standard network monitoring and reporting package include, and at what frequency? How are planned maintenance windows communicated and scheduled? What monitoring tools do you use, and will we have visibility into the dashboards? How do you handle GDPR compliance in relation to network access logs and data handling? What is your process for escalating a fault that exceeds your first-line resolution capability? Can you cover both physical cabling maintenance and logical network configuration, or will we need a separate contractor for each? Impulso Tecnológico's model is designed to answer these questions with a single provider — covering structured cabling, managed network services, and security — which eliminates the coordination overhead that multi-vendor arrangements typically generate. For organisations across Spain, Portugal, and internationally, this integrated approach is a practical differentiator.
Network infrastructure maintenance is most effective when it is planned, not improvised. Start by establishing your monitoring baseline and maintenance cadence, then layer in security controls and change management discipline so that your network can absorb growth and change without accumulating hidden risk. Whether you manage this internally or work with a specialist provider, the goal is the same: a network that supports your business reliably, is auditable when needed, and recovers quickly when the unexpected occurs. If you are ready to move from reactive firefighting to structured network resilience and recovery planning, the next step is a conversation about what your current infrastructure actually looks like — and where the gaps are.
