
El mantenimiento de infraestructuras de red abarca el conjunto de acciones preventivas y correctivas que garantizan la conectividad, la seguridad y el rendimiento de todos los componentes de red de una organización: cableado, switches, routers, firewalls, puntos de acceso y sistemas de backup.
Cuando una empresa ignora este mantenimiento, los problemas no tardan en aparecer: cortes de conectividad en horas críticas, vulnerabilidades sin parchear que abren la puerta a ataques, equipos que degradan su rendimiento de forma silenciosa y costes de reparación urgente que multiplican el presupuesto previsto. La diferencia entre una red que "va tirando" y una red que sostiene el negocio está, precisamente, en la disciplina del mantenimiento.
Un plan bien estructurado combina revisiones programadas, monitoreo continuo, gestión de parches y verificación periódica de las copias de seguridad. El resultado es predecible: menos incidencias, mayor disponibilidad y una infraestructura preparada para crecer sin convertirse en un riesgo operativo.
Qué incluye el mantenimiento de infraestructuras de red
El mantenimiento de infraestructuras de red no es una tarea puntual ni se reduce a intervenir cuando algo falla. Su alcance real abarca cuatro dimensiones interdependientes: la capa física (cableado estructurado, patch panels, fibra óptica), la capa lógica (configuración de switches, VLANs, routing), la capa de seguridad (firewalls, IPS, control de accesos, gestión de parches) y la capa de continuidad (copias de seguridad, verificación de restauración, planes de recuperación).
En Impulso Tecnológico, con más de 25 años de experiencia en servicios IT gestionados, partimos de una premisa concreta: el mantenimiento de red empieza por la certificación del cableado. Sin una base física documentada y en buen estado, cualquier intervención sobre la capa lógica o de seguridad tiene los pies de barro. Por eso combinamos el diseño, montaje y certificación de cableado estructurado con el soporte técnico continuo, resolviendo incidencias con un modelo coordinado que asigna cada requerimiento al técnico más cercano con las competencias necesarias.
| Dimensión | Qué incluye | Frecuencia típica | Impacto si se descuida |
|---|---|---|---|
| Capa física (cableado) | Inspección de conectores, certificación, limpieza de CPD, eliminación de cables abandonados | Semestral / anual | Cortes intermitentes, degradación de velocidad, fallos difíciles de diagnosticar |
| Capa lógica (red) | Revisión de configuraciones, actualizaciones de firmware, auditoría de VLANs y routing | Mensual / trimestral | Inestabilidad, bucles, pérdida de segmentación |
| Capa de seguridad | Gestión de parches, hardening, revisión de reglas de firewall, control de accesos | Mensual / continuo | Vulnerabilidades explotables, brechas de datos, incumplimiento normativo |
| Capa de continuidad | Verificación de backups, pruebas de restauración, actualización del plan de recuperación | Semanal / mensual | Pérdida de datos irrecuperable, tiempos de recuperación inasumibles |
Objetivos del mantenimiento: conectividad, seguridad y rendimiento
Tres objetivos concretos justifican cualquier plan de mantenimiento preventivo de red. El primero es la conectividad: que cada usuario, dispositivo y aplicación disponga del acceso que necesita, sin cortes ni degradaciones. El segundo es la seguridad: que la infraestructura no sea el eslabón débil ante amenazas externas o internas, lo que exige revisiones periódicas de firewalls, segmentación de VLANs y aplicación sistemática de parches. El tercero es el rendimiento: que la red soporte la carga real de trabajo —videoconferencias, transferencias masivas de datos, accesos simultáneos— sin convertirse en un cuello de botella. Estos tres objetivos no son independientes; un cableado mal terminado puede causar pérdida de paquetes que se manifiesta como lentitud y que, además, complica el diagnóstico de incidentes de seguridad.
Alcance por capas: red, seguridad, hardware/software y operación
Cuando el mantenimiento correctivo entra en juego, el proceso sigue una secuencia clara: diagnóstico, contención, reparación o sustitución y verificación. El diagnóstico correcto es el paso más crítico, porque un síntoma —por ejemplo, pérdida de conectividad en una planta— puede tener origen en el cableado, en la configuración de un switch o en un fallo de hardware. La compatibilidad entre equipos es un factor que se subestima con frecuencia: sustituir un switch por un modelo diferente sin revisar las configuraciones de VLAN o los protocolos de spanning tree puede generar nuevos problemas. En proyectos de mantenimiento para redes distribuidas en múltiples sedes, como los que gestiona Impulso Tecnológico, este control de compatibilidad se documenta en un inventario centralizado que facilita decisiones de reemplazo sin improvisación.
Preventivo vs correctivo: cuándo aplica cada enfoque
El mantenimiento preventivo actúa antes de que el problema exista: revisiones programadas, aplicación de parches de firmware, saneamiento de cableado y verificación de configuraciones. El correctivo responde cuando el fallo ya ha ocurrido. La pregunta práctica es cuánto invertir en cada enfoque. La respuesta depende de la criticidad de la red: en entornos donde un corte de 30 minutos implica pérdidas económicas directas —logística, producción, sanidad—, el peso del presupuesto debe estar en el preventivo. En redes menos críticas, un modelo mixto con revisiones trimestrales y soporte correctivo con SLA de soporte definido puede ser suficiente. La continuidad del negocio se refuerza con copias de seguridad verificadas periódicamente: no basta con que el backup exista; hay que comprobar que la restauración funciona en los tiempos previstos.

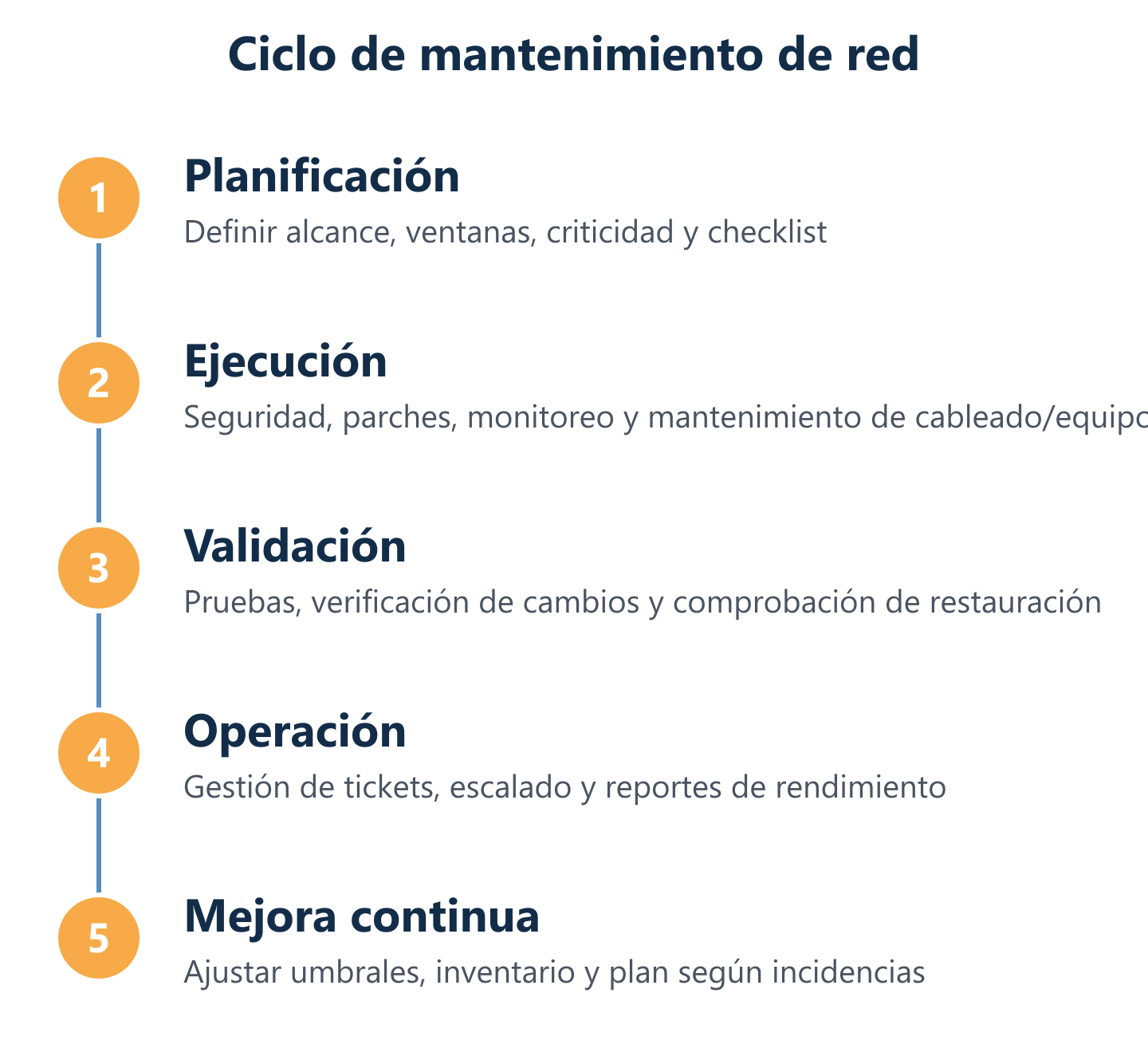
Cómo se ejecuta: checklist técnico y ciclo operativo
Un ciclo operativo de mantenimiento de red efectivo no es una lista de tareas sin orden; es un flujo con fases secuenciales donde cada paso alimenta al siguiente. En Impulso Tecnológico, el ciclo se apoya en tres pilares: la documentación actualizada de la infraestructura (inventario de equipos, topología, versiones de firmware y esquema de cableado), la monitorización continua con umbrales de alerta predefinidos, y la ejecución de intervenciones —tanto programadas como reactivas— con registro trazable de cada acción.
Este enfoque integra el mantenimiento del cableado de redes informáticas certificado con el soporte remoto e in situ, y refuerza la continuidad operativa con copias de seguridad gestionadas mediante tecnología Veeam, cuya restauración se verifica de forma periódica. En un proyecto de mantenimiento para una cadena de más de quince oficinas distribuidas en España, este modelo permitió alcanzar una disponibilidad superior al 99,5% y reducir el tiempo medio de resolución de incidencias en un 65%.
- Inventario y documentación: Registrar todos los activos de red (switches, routers, firewalls, APs, servidores, cableado) con versiones de firmware y fechas de garantía.
- Auditoría de seguridad: Revisar reglas de firewall, segmentación de VLANs, control de accesos y estado de parches pendientes.
- Monitoreo de rendimiento: Verificar métricas de latencia, pérdida de paquetes y saturación de ancho de banda; ajustar umbrales de alerta.
- Mantenimiento de hardware y cableado: Inspeccionar conectores, limpiar CPD, actualizar firmware de equipos y gestionar reemplazos por fin de vida.
- Verificación de backups: Comprobar que las copias de seguridad se han ejecutado correctamente y realizar pruebas de restauración documentadas.
- Informe y planificación: Generar reporte de estado, registrar incidencias abiertas y cerradas, y programar las próximas intervenciones.
Checklist de seguridad: auditoría, parches y reducción de superficie de ataque
El hardening de la red empieza por auditar lo que ya existe. Las reglas de firewall acumulan excepciones con el tiempo: puertos abiertos que ya no tienen uso, accesos remotos que se habilitaron para un proyecto puntual y nunca se cerraron, o políticas de IPS desactualizadas. Una revisión trimestral de estas reglas, combinada con la gestión sistemática de parches de firmware en switches, routers y firewalls, reduce de forma medible la superficie de ataque. En entornos gestionados con tecnología Sophos o Fortinet —fabricantes con los que trabaja Impulso Tecnológico—, esta gestión se puede automatizar con alertas cuando un equipo lleva más de 30 días sin actualizar. La segmentación mediante VLANs y el control de accesos basado en roles completan el perímetro interno, evitando que un dispositivo comprometido tenga visibilidad sobre toda la red.
Monitoreo de red: métricas clave (latencia, pérdida, saturación) y umbrales
El monitoreo de red y rendimiento no sirve de nada sin umbrales bien definidos. Las tres métricas fundamentales son: latencia (tiempo de ida y vuelta entre dos puntos; valores superiores a 50 ms en redes LAN ya indican un problema), pérdida de paquetes (cualquier valor por encima del 0,1% en tráfico crítico merece investigación inmediata) y saturación de ancho de banda (cuando un enlace supera el 80% de capacidad de forma sostenida, es señal de que hay que revisar el dimensionamiento o el tráfico anómalo). Las herramientas de monitoreo generan alertas automáticas cuando se superan estos umbrales, lo que permite actuar antes de que el usuario note la degradación. El tráfico anómalo —picos inexplicables en horarios fuera de lo habitual— también puede ser indicador de una brecha de seguridad activa.
Mantenimiento de cableado y equipos: estado, compatibilidad y reemplazos
El cableado estructurado es la capa más ignorada del mantenimiento de red y, paradójicamente, la que más incidencias silenciosas genera. Un conector RJ45 mal terminado, un cable categoría 5e en un entorno que ya opera a 10 Gbps, o un patch panel con cables abandonados que generan interferencias: estos problemas no aparecen en los logs del firewall, pero degradan el rendimiento de toda la red. La revisión física periódica —con certificación de los tramos críticos y limpieza del CPD— es parte del ciclo de mantenimiento preventivo de red. En cuanto a los equipos activos, la gestión de reemplazos debe anticiparse al fin de vida (EOL) del fabricante: un switch sin soporte de firmware es un equipo sin parches de seguridad, independientemente de que siga funcionando. Mantener un inventario actualizado con fechas de EOL permite planificar sustituciones sin urgencias.
Cómo elegir un proveedor y plan de mantenimiento
Elegir un proveedor de mantenimiento de infraestructuras de red es una decisión que afecta directamente a la disponibilidad operativa de la empresa. No todos los proveedores cubren las mismas capas ni ofrecen el mismo nivel de trazabilidad. Antes de firmar un contrato, conviene evaluar al menos cinco dimensiones: el alcance real del servicio (¿incluye cableado físico, seguridad y backups, o solo soporte de hardware?), la cobertura geográfica (especialmente relevante para empresas con múltiples sedes), los niveles de servicio y tiempos de respuesta comprometidos, las herramientas de gestión y visibilidad (ticketing, inventario, reportes), y la experiencia certificada con los fabricantes de tu infraestructura.
Impulso Tecnológico propone un modelo de soporte mixto —asistencia in situ programada combinada con soporte remoto— con coordinación centralizada que asigna cada incidencia al técnico más cercano con las competencias necesarias. Cuando la situación lo requiere, el escalado a especialistas senior se produce de forma inmediata. Los contratos incluyen SLA de soporte definidos y reportes periódicos de estado, lo que garantiza visibilidad completa sobre el estado de la infraestructura. Para empresas con presencia en varias provincias o países, este modelo ya ha demostrado su eficacia en proyectos de cobertura nacional.
- Alcance documentado: Exige que el contrato especifique qué capas cubre (física, lógica, seguridad, continuidad) y qué queda excluido.
- Cobertura geográfica verificable: Comprueba si el proveedor tiene técnicos propios o subcontrata en tus ubicaciones; la diferencia en tiempos de respuesta puede ser significativa.
- SLA con penalizaciones reales: Un SLA sin consecuencias contractuales por incumplimiento es solo una promesa; verifica que existan mecanismos de compensación.
- Certificaciones de fabricante: Para redes con tecnología Cisco, Aruba, Fortinet o Sophos, el proveedor debe acreditar certificación activa, no solo experiencia declarada.
- Herramientas de visibilidad: Acceso a un portal o dashboard donde puedas ver el estado de tickets, inventario y métricas de red en tiempo real.
- Experiencia en tu sector: Un proveedor con casos documentados en industria, logística o sanidad conoce las particularidades operativas que afectan al diseño del mantenimiento.
Criterios de selección: alcance por sedes, criticidad y compatibilidad tecnológica
Las empresas con múltiples sedes enfrentan un reto específico: la infraestructura de red no es homogénea. Un centro logístico de nueva construcción tiene condicionantes distintos a una oficina en un edificio histórico con limitaciones estructurales para el cableado. El proveedor debe demostrar capacidad para adaptar el mantenimiento a cada entorno, no aplicar una plantilla genérica. La criticidad de las aplicaciones que corren sobre la red determina el nivel de servicio necesario: si un corte de conectividad paraliza la producción o impide el acceso a sistemas clínicos, el tiempo de respuesta comprometido debe ser inferior a cuatro horas. La compatibilidad tecnológica también es un criterio de selección: un proveedor certificado por los fabricantes de tu infraestructura —Cisco, Aruba, Fortinet— puede intervenir sin invalidar garantías ni introducir configuraciones no soportadas.
Comparativa de modelos: soporte reactivo, mantenimiento preventivo y servicio gestionado
Existen tres modelos predominantes en el mercado, con diferencias sustanciales en coste, riesgo y visibilidad. El soporte reactivo (break-fix) solo interviene cuando hay un fallo: el coste por incidencia puede ser bajo, pero la acumulación de problemas no resueltos y los tiempos de inactividad no planificados suelen encarecer el coste total. El mantenimiento preventivo añade revisiones programadas y gestión de parches, reduciendo la frecuencia de fallos pero requiriendo un proveedor con metodología y herramientas de monitoreo. El servicio gestionado (MSP) integra las dos capas anteriores con visibilidad continua, gestión de inventario, reportes periódicos y un interlocutor único para toda la infraestructura IT. Este último modelo es el que permite operar con contratos mensuales de coste predecible y SLA de soporte garantizados, eliminando las sorpresas presupuestarias que genera el modelo reactivo.
Roadmap de implantación: 30-60-90 días para estabilizar sin interrumpir
Implantar un plan de mantenimiento en una red en producción requiere una secuencia que minimice el riesgo operativo. Los primeros 30 días deben dedicarse al diagnóstico: auditoría completa de la infraestructura existente, inventario de activos, identificación de vulnerabilidades críticas y documentación del estado real del cableado. Entre los días 31 y 60, se ejecutan las acciones de mayor impacto sin interrumpir operaciones: aplicación de parches urgentes, corrección de configuraciones de seguridad, activación del monitoreo continuo y verificación del estado de las copias de seguridad. Del día 61 al 90, se estabiliza el ciclo operativo: se definen los umbrales de alerta definitivos, se establece la cadencia de revisiones preventivas, se realizan las primeras pruebas de restauración documentadas y se entrega el primer informe de estado al cliente. Este roadmap permite gestionar el cambio sin generar nuevos riesgos durante la transición.
Si tu red sostiene operaciones críticas, medirla solo por el número de reparaciones realizadas es un error de perspectiva. Los indicadores que realmente importan son la disponibilidad acumulada, el tiempo medio de resolución de incidencias y la ausencia de vulnerabilidades sin parchear. Un plan de mantenimiento bien ejecutado convierte la infraestructura de red en un activo predecible, no en una fuente de incertidumbre. Si necesitas evaluar qué modelo de mantenimiento se ajusta a tu infraestructura —número de sedes, tipo de cableado, criticidad de aplicaciones y ventanas de intervención disponibles—, el punto de partida es un diagnóstico técnico que documente el estado real antes de comprometer ningún SLA. Puedes conocer cómo gestionamos proyectos de este tipo consultando nuestro caso de éxito en implementación de red corporativa o explorar el alcance de nuestro servicio de redes corporativas.
