
Comprehensive network threat management is the coordinated practice of identifying, protecting against, detecting, responding to, and recovering from threats across all network-connected assets—traffic flows, endpoints, identities, and supporting systems—using layered controls, continuous monitoring, and documented response workflows.
Most organisations discover their security gaps only after an incident: a misconfigured firewall rule, an unmonitored segment, or a backup that was never tested. By that point, the cost is already operational downtime, data exposure, or both. The difference between a contained incident and a business-disrupting breach is rarely the sophistication of the attack—it is the consistency of the controls and the speed of the response.
A genuinely comprehensive approach closes that gap by treating threat management as a continuous lifecycle rather than a point-in-time product. It integrates network monitoring, threat intelligence, segmentation-aware protection, and tested incident response playbooks into a single operational programme. The result is measurable: reduced dwell time, faster containment, and recovery that can be validated before the next audit cycle.
What "Comprehensive Network Threat Management" Covers (and what it doesn't)
The word "comprehensive" is doing a lot of work in this context. Many organisations believe they have network threat management in place because they run a firewall and an antivirus agent. In practice, those controls address only the entry and endpoint layers—leaving traffic analysis, identity behaviour, email-borne threats, and backup integrity largely unmonitored.
Truly comprehensive network threat management spans the full threat lifecycle: prevent, detect, respond, and recover. It applies consistent controls and visibility across every layer where threats can move—north-south perimeter traffic, east-west lateral movement between segments, user identity and access paths, cloud workloads, and the backup systems that attackers increasingly target to neutralise recovery options.
At Impulso Tecnológico, we align monitoring, hardening, and rapid remediation under clear SLAs so that network threats are identified and handled before they escalate into downtime events or reportable security incidents. This means integrating Sophos and Fortinet security controls with continuous health monitoring and Veeam-backed recovery capabilities under a single managed service model.
| Capability Area | Perimeter-Only Security | Vulnerability Management | Comprehensive Network Threat Management |
|---|---|---|---|
| Scope | Network edge (firewall, IPS) | Known weaknesses in assets | All network layers, endpoints, identities, email, backups |
| Primary focus | Block known bad traffic | Patch and remediate exposures | Detect, contain, and recover from active threats |
| Detection capability | Signature-based only | Scanning and scoring | Signatures + IOCs + behavioural models + TTP analytics |
| Response workflow | Block or alert | Remediation ticket | Documented playbooks with containment and recovery steps |
| Threat intelligence use | Feed-based rule updates | CVE prioritisation | Integrated into triage, detection tuning, and response |
| Recovery validation | Not included | Not included | Tested backup restoration and recovery KPIs |
Threat management vs vulnerability vs risk: what changes in network operations
Vulnerability management asks: "What weaknesses exist in our assets?" Risk management asks: "What is the business impact if those weaknesses are exploited?" Threat management asks a different question entirely: "What is actively trying to harm us, and can we detect and stop it in time?"
In network operations, this distinction matters operationally. Vulnerability programmes produce patch queues and CVSS scores. Threat management produces detection rules, alert triage workflows, and containment actions. The two complement each other—an unpatched vulnerability that is actively exploited in the wild becomes a threat management priority, not just a remediation ticket. Comprehensive network threat management covers the full lifecycle—identify, protect, detect, respond, recover—applied to network segments and the services running across them, using threat behaviour as the primary signal rather than asset exposure alone.
Network scope: traffic, identity, endpoints, email paths, and backup environments
"Comprehensive" means consistent controls and visibility across every surface where threats can operate. In a typical business network, that includes: inbound and outbound perimeter traffic; lateral east-west traffic between VLANs and segments; endpoint behaviour on workstations, servers, and mobile devices; user identity and authentication events (Active Directory, Azure AD, MFA logs); email delivery paths, which remain the primary initial access vector for phishing and malware; cloud workloads and SaaS application access; and backup and recovery systems, which ransomware operators specifically target to eliminate restoration options. Leaving any of these surfaces unmonitored creates a blind spot that attackers can exploit without triggering a single alert. Segmentation-aware protection—knowing which segments should communicate with which, and alerting on deviations—is a foundational requirement for genuine network-wide coverage.
Operational outcomes: reduced downtime, faster containment, and recovery validation
The measurable outputs of a comprehensive programme are what distinguish it from a compliance checkbox exercise. Three outcomes matter most in network operations: reduced dwell time (the window between initial compromise and detection, which industry data consistently shows averages weeks or months without active monitoring); faster containment (isolating affected segments or devices before lateral movement spreads the incident); and validated recovery (confirming that backups are intact, clean, and restorable before an incident occurs, not during one).
These outcomes also define the boundary with vulnerability management. Comprehensive network threat management complements patching programmes but focuses on threat behaviour, detection signal quality, and response speed. A patched network with no detection capability is still vulnerable to zero-day exploitation and insider misuse—areas where behavioural monitoring and documented incident response playbooks provide the operational safety net.

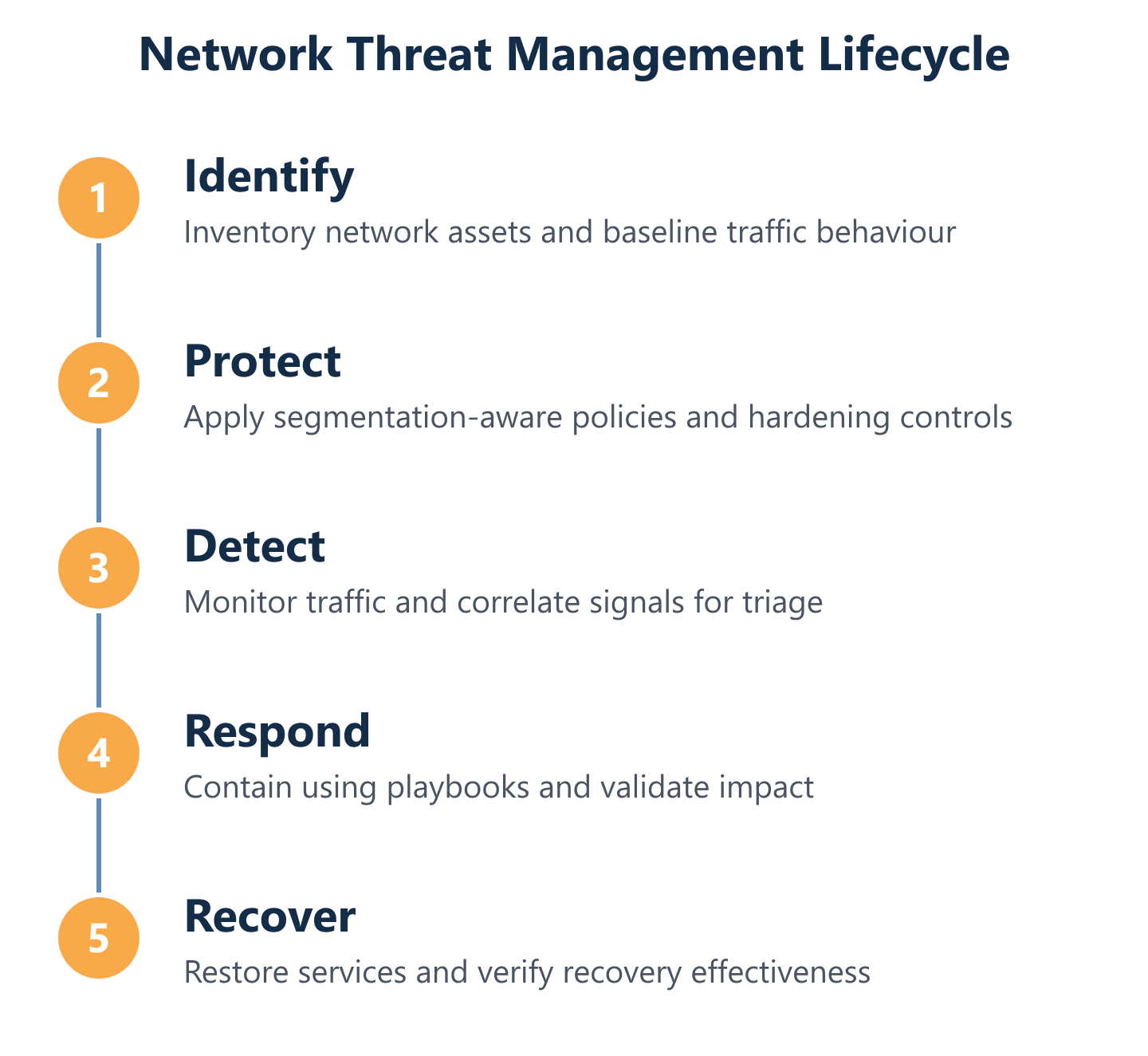
The NIST CSF Threat Management Lifecycle for Networks (Identify→Recover)
The NIST Cybersecurity Framework's five functions—Identify, Protect, Detect, Respond, Recover—provide the most widely adopted structure for building a network threat management programme. Their value is not theoretical: each function maps directly to operational decisions that determine whether a threat is contained in minutes or discovered weeks later.
At Impulso Tecnológico, our managed IT approach operationalises this lifecycle continuously. We check network health and performance in real time, trigger automated alerts for our technicians to investigate, and remediate remotely where possible—backed by a cybersecurity layer using Sophos and Fortinet and recovery protection through Veeam. GDPR-aligned documentation of controls and incident response procedures is treated as part of the programme from day one, not added retroactively.
- Identify: Build a complete inventory of network assets, traffic flows, and data paths—this is the foundation for every subsequent control decision.
- Protect: Apply segmentation-aware policies, access controls, patch management, and security hardening consistently across all identified assets and segments.
- Detect: Deploy layered monitoring covering traffic anomalies, endpoint behaviour, identity events, and log correlation—with tuned alert triage rules to reduce noise.
- Respond: Execute documented incident response playbooks that specify containment steps, escalation paths, and communication procedures for each threat scenario.
- Recover: Validate that backup systems are intact and restorable, confirm network integrity post-incident, and update controls based on lessons learned.
Identify: network asset inventory, segmentation mapping, and baseline traffic behaviour
You cannot protect or detect threats against assets you do not know exist. The Identify function starts with building an accurate, maintained inventory of every network-connected device, service, and data flow—including shadow IT, unmanaged endpoints, and cloud-connected systems that often escape traditional discovery tools.
Segmentation mapping goes one level deeper: documenting which VLANs, subnets, and zones should communicate with which, and under what conditions. This baseline becomes the reference point for anomaly detection—any traffic pattern that deviates from the documented norm becomes a candidate for investigation. Establishing baseline traffic behaviour (typical bandwidth, connection frequency, protocol distribution by segment) is equally important; without it, even a sophisticated monitoring platform generates alerts that analysts cannot prioritise. At Impulso Tecnológico, we treat this inventory and baseline phase as the prerequisite for every monitoring and hardening decision that follows.
Protect & Detect: policy enforcement, monitoring coverage, and alert triage rules
Protection controls must match how threats actually move through networks—not just how they enter. Firewall policies, endpoint protection, patch management, and MFA enforcement are table-stakes; segmentation-aware protection adds the layer that limits lateral movement once a perimeter control is bypassed. Fortinet and Sophos solutions, for example, allow policy enforcement at the segment level with visibility into east-west traffic that traditional perimeter firewalls do not provide.
Detection coverage requires both breadth (monitoring all relevant surfaces) and precision (alert triage rules that distinguish genuine threats from operational noise). Poorly tuned detection generates alert fatigue, which is itself a security risk—analysts begin ignoring or bulk-closing alerts, and real incidents are missed. Effective triage rules combine severity thresholds, asset criticality context, and threat intelligence enrichment so that the alerts reaching a technician are already prioritised and actionable, reducing mean time to investigate.
Respond & Recover: incident playbooks, containment workflows, and recovery validation
Incident response playbooks define, in advance, exactly what happens when a specific threat type is detected: who is notified, which containment actions are taken (isolate segment, disable account, block IP range), what evidence is preserved, and how the incident is documented for GDPR compliance purposes. Without pre-defined playbooks, response time is consumed by decision-making under pressure—the worst possible moment for ambiguity.
Containment workflows should be segmentation-aware: isolating a compromised VLAN rather than taking down the entire network minimises operational impact. Recovery validation closes the lifecycle—confirming that Veeam backups are intact, clean (not encrypted or corrupted by ransomware), and restorable within the organisation's recovery time objective. KPIs worth tracking include mean time to detect (MTTD), mean time to contain (MTTC), and recovery time against the documented RTO—these figures make the programme's effectiveness measurable and auditable, which matters both operationally and for regulatory reporting.
Detection Methods, Intelligence Integration, and Scale (UTM, MDR, XDR)
Detection capability is where most network threat management programmes either hold or fail under pressure. A single detection method—signature-based rules, for example—is effective against known threats but blind to novel malware variants, living-off-the-land techniques, and insider misuse that generates no known-bad signatures. Evolving threats require layered detection across multiple signal types, enriched with current threat intelligence and operationalised at a scale that does not overwhelm the team managing it.
At Impulso Tecnológico, we centralise monitoring, maintenance, and security under one provider to prevent the configuration drift that creates detection gaps over time. Our hybrid onsite and remote delivery model ensures that detection coverage remains consistent across distributed environments—whether a client operates from a single office in Spain or across multiple international locations. Partners including Sophos and Fortinet provide the technology layer; our experienced technicians provide the investigative and triage capability that turns alerts into resolved incidents.
- Layered detection reduces blind spots: No single method covers all threat types; combining signatures, IOCs, behavioural models, and TTP analytics provides overlapping coverage that is harder for attackers to evade entirely.
- Threat intelligence accelerates triage: Enriching alerts with current intelligence feeds reduces the time analysts spend determining whether an anomaly is a genuine threat or benign noise.
- Data unification eliminates fragmentation: Correlating signals from network, endpoint, identity, and cloud sources into a single view is the operational prerequisite for consistent detection across all surfaces.
- Automation reduces analyst burden: SOC automation handles repetitive triage tasks—IP lookups, hash checks, alert enrichment—so human expertise is applied to decisions that require judgement.
- Delivery model selection matters: UTM, MDR, and XDR each address different coverage and response requirements; choosing the wrong model leaves gaps that attackers can exploit.
Detection methods that work on networks: signatures, IOCs, models, and TTP behaviour
Four detection methods apply to network environments, each with distinct strengths. Signature-based detection matches traffic or file patterns against a known-bad database—fast and low-noise for known threats, but ineffective against novel or obfuscated variants. Indicator of Compromise (IOC) detection matches observable artefacts—malicious IP addresses, domain names, file hashes—against threat intelligence feeds; effective for tracking known threat actor infrastructure but dependent on intelligence currency. Behavioural modelling establishes normal baselines and flags statistical deviations—unusual data transfer volumes, abnormal login times, unexpected protocol use—catching threats that generate no known signatures. TTP-based analytics map observed network behaviour to MITRE ATT&CK techniques, identifying attacker tradecraft regardless of the specific tool used. Effective network threat management uses all four in combination: signatures and IOCs for speed on known threats; models and TTP analytics for coverage against unknown and evolving ones.
Threat intelligence integration: from research signals to actionable monitoring and faster triage
Threat intelligence improves network monitoring in three concrete ways: it updates detection rules with current attacker infrastructure (domains, IPs, file hashes) before those indicators appear in your environment; it provides context that accelerates triage—an alert involving an IP address linked to an active ransomware campaign is immediately higher priority than one involving an unknown address; and it informs the tuning of behavioural models by identifying which TTPs are currently active in your sector.
Intelligence-led defence, as practised by teams like Cisco Talos, demonstrates that the gap between a threat appearing "in the wild" and a detection rule being deployed can be reduced from days to hours when intelligence is operationally integrated rather than reviewed periodically. For network operations, this means connecting threat intelligence feeds directly into your SIEM or monitoring platform—not storing them in a separate research portal—so that enrichment happens automatically at alert generation, not manually during investigation.
Operating at scale: SOC enablement, automation, data unification, and UTM vs MDR vs XDR
Fragmented security tools create blind spots that are operationally dangerous: an endpoint alert that never correlates with a network anomaly from the same host means two separate incidents are investigated instead of one coordinated attack. Data unification—aggregating signals from network monitoring, endpoint detection, identity logs, and cloud access into a single platform—is the foundational requirement for operating at scale without proportionally scaling analyst headcount.
Three delivery models address different coverage and response needs. UTM (Unified Threat Management) consolidates multiple perimeter controls—firewall, IPS, URL filtering, VPN—into one appliance; effective for SMEs seeking consolidated perimeter protection but limited in cross-domain detection depth. MDR (Managed Detection and Response) adds a managed human layer for 24-hour monitoring and response, suitable when internal SOC capacity is limited. XDR (Extended Detection and Response) unifies telemetry across network, endpoint, identity, and cloud into a single detection and response platform, providing the broadest coverage for organisations with complex, multi-domain environments. For a detailed comparison of these approaches in the context of your security programme, our cybersecurity for businesses guide covers selection criteria in depth.
Network threats do not respect organisational boundaries, tool categories, or business hours. The organisations that contain incidents quickly are not necessarily those with the largest security budgets—they are the ones that have aligned their controls, detection signals, and response workflows into a single, tested lifecycle. If your current programme has gaps in visibility, inconsistent controls across segments, or untested recovery procedures, those gaps represent real operational risk. Impulso Tecnológico's managed approach—combining proactive monitoring, Sophos and Fortinet security controls, Veeam-backed recovery, and clear SLA-driven response—is designed to close those gaps before an attacker finds them. For organisations ready to assess where their network threat management programme stands today, a structured computer network audit is the logical starting point, and our IT security plan guide provides the implementation framework that follows.
