
La gestión integral de amenazas de red es el proceso continuo que combina identificación de activos, gestión de vulnerabilidades en red, controles de seguridad, monitoreo de seguridad y telemetría, y orquestación de respuesta en un único ciclo operativo, con el objetivo de reducir la ventana de exposición y minimizar el impacto de cualquier incidente.
Las organizaciones que tratan la seguridad de red como una suma de herramientas independientes acaban pagando el precio: brechas que pasan semanas sin detectarse, parches que llegan tarde y respuestas descoordinadas que convierten un incidente menor en una interrupción de negocio. El problema no es la falta de tecnología, sino la ausencia de un ciclo unificado que conecte cada fase.
Un programa estructurado cambia esa ecuación. Cuando visibilidad, controles, detección y recuperación ante ransomware operan de forma coordinada bajo un mismo modelo de gestión, el tiempo medio de detección y remediación cae de forma significativa y la capacidad de demostrar cumplimiento normativo se vuelve sistemática, no reactiva. En Impulso Tecnológico llevamos más de 25 años diseñando y operando este tipo de arquitecturas para empresas que no pueden permitirse interrupciones.
Qué significa "gestión integral" aplicada a amenazas en redes modernas
Hablar de gestión integral de amenazas de red no es hablar de un producto ni de una herramienta: es hablar de un modelo operativo que cubre el ciclo completo desde la identificación del riesgo hasta la recuperación del servicio. La desaparición del perímetro tradicional —acelerada por la adopción de cloud, el trabajo remoto y la proliferación de dispositivos IoT— obliga a tratar la red como una superficie dinámica y heterogénea, donde los activos cambian, los accesos se multiplican y los vectores de ataque evolucionan constantemente.
En Impulso Tecnológico estructuramos este proceso alineado con el Marco de Ciberseguridad del NIST, que organiza las capacidades en cinco funciones: Identificar, Proteger, Detectar, Responder y Recuperar. Este marco no es solo una referencia teórica; es la columna vertebral que permite asignar responsabilidades, medir madurez y priorizar inversiones de forma coherente.
| Función NIST | Alcance en red | Ejemplo de control | Riesgo si se omite |
|---|---|---|---|
| Identificar | Inventario de activos, mapeo de dependencias | Descubrimiento automatizado de dispositivos | Activos no gestionados expuestos |
| Proteger | Segmentación, firewalls, parcheo | Firewall de nueva generación (NGFW) | Movimiento lateral sin fricción |
| Detectar | Monitoreo de tráfico, correlación de eventos | IDS/IPS, análisis de telemetría | Brechas sin detectar durante semanas |
| Responder | Contención, investigación, remediación | Playbooks automatizados en SOC | Escalada innecesaria del incidente |
| Recuperar | Restauración de servicios, lecciones aprendidas | Backup y disaster recovery con Veeam | Tiempo de inactividad prolongado |
De "seguridad por capas" a operación coordinada
Durante años, el modelo de defensa en profundidad se interpretó como la suma de capas independientes: un firewall aquí, un antivirus allá, un sistema de backup sin conexión con el resto. Ese enfoque genera silos tecnológicos donde cada herramienta genera alertas que nadie correlaciona, y donde la respuesta a un incidente depende de que alguien recuerde qué hace cada sistema.
La gestión integral de amenazas de red rompe esa lógica. No se trata de añadir más capas, sino de hacer que cada capa comunique con las demás dentro de un ciclo continuo: identificar activos y vulnerabilidades, aplicar controles, detectar anomalías, responder de forma coordinada y recuperar el servicio con el menor impacto posible. La coordinación entre funciones es el diferencial real.
Funciones del ciclo: identificar, proteger, detectar, responder y recuperar
El perímetro de red ya no es una línea; es un conjunto de puntos de exposición distribuidos entre oficinas, centros de datos, entornos cloud, endpoints remotos, dispositivos IoT y conexiones de terceros. Cada uno de esos puntos puede convertirse en vector de entrada si no está inventariado, protegido y monitorizado.
Las cinco funciones del ciclo NIST responden a esa realidad: Identificar establece qué hay que proteger; Proteger reduce la probabilidad de explotación; Detectar acorta el tiempo hasta el descubrimiento de un incidente; Responder limita el daño; y Recuperar garantiza la continuidad del negocio. Ninguna función opera de forma eficaz sin las demás: un programa que solo parchea pero no detecta sigue siendo vulnerable a exploits de día cero.
Por qué la telemetría y la correlación son parte del concepto integral
Un escaneo de vulnerabilidades puntual ofrece una fotografía del estado de la red en un momento dado; la telemetría continua ofrece la película completa. La diferencia es crítica: los atacantes no esperan al próximo escaneo programado para explotar una configuración incorrecta o una credencial comprometida.
La correlación de eventos —cruzar logs de firewall, tráfico de red, actividad de endpoints y alertas de sistemas— es lo que transforma datos dispersos en inteligencia accionable. Un programa unificado de gestión de ciberamenazas que integre telemetría en tiempo real reduce los puntos ciegos que permiten que un ataque avance sin ser detectado, y mejora la coordinación entre el equipo de operaciones de red y el equipo de seguridad. Esa coordinación es, precisamente, la diferencia entre contener un incidente en horas y descubrirlo semanas después.

Mapa de activos y visibilidad: base para eliminar "puntos ciegos"
No se puede proteger lo que no se conoce. Antes de implementar cualquier control de seguridad de red, una organización necesita saber exactamente qué activos componen su infraestructura, qué servicios exponen, con qué otros sistemas se comunican y cuál es su nivel de criticidad para el negocio. Sin ese inventario, la gestión de vulnerabilidades en red opera a ciegas.
En Impulso Tecnológico centralizamos la gestión bajo un único proveedor para mejorar la correlación de eventos en entornos distribuidos que combinan infraestructura on-premises, servicios en la nube y endpoints remotos. Esa centralización elimina la fricción operativa que genera tener múltiples proveedores con visibilidades parciales y sin capacidad de cruzar información.
- Descubrimiento automatizado: ejecutar herramientas de escaneo activo y pasivo para detectar todos los dispositivos, sistemas y servicios conectados a la red, incluidos los no gestionados.
- Clasificación por criticidad: asignar a cada activo un nivel de importancia para el negocio (crítico, alto, medio, bajo) en función de los datos que maneja y los procesos que soporta.
- Mapeo de dependencias: identificar qué activos se comunican entre sí, qué servicios externos consumen y qué rutas de acceso existen desde el exterior.
- Registro de configuraciones base: documentar el estado de configuración esperado de cada sistema para detectar desviaciones que puedan indicar una intrusión o un error.
- Actualización continua del inventario: automatizar la detección de cambios (nuevos dispositivos, servicios añadidos, cambios de configuración) para que el mapa de activos refleje siempre el estado real de la red.
Inventario de red y servicios: qué registrar y con qué frecuencia
Un inventario de red útil no se limita a listar direcciones IP. Debe registrar para cada activo: nombre y tipo de dispositivo, sistema operativo y versión, servicios y puertos activos, propietario funcional, ubicación física o lógica, y fecha del último cambio de configuración. Las dependencias entre sistemas son igualmente críticas: un servidor de aplicaciones que se comunica con una base de datos expuesta representa un riesgo diferente a uno aislado.
La frecuencia de actualización debe adaptarse al dinamismo del entorno. En redes con alta rotación de dispositivos (entornos con BYOD o IoT), el descubrimiento debe ser continuo o al menos diario. En infraestructuras más estables, una revisión semanal automatizada complementada con una auditoría manual trimestral —como la que realizamos en Impulso Tecnológico— es suficiente para mantener el inventario fiable y alineado con la realidad operativa.
Fuentes de datos: logs, flujos, endpoints y configuraciones
La observabilidad de una red depende de la diversidad y calidad de sus fuentes de datos. Los logs de firewall y de sistemas operativos registran eventos de acceso y errores; los flujos de red (NetFlow, sFlow) revelan patrones de comunicación y volúmenes de tráfico; los agentes de endpoint capturan actividad de procesos, conexiones salientes y cambios en el sistema de archivos; y los registros de configuración documentan el estado de cada dispositivo en un momento dado.
Ninguna fuente por sí sola ofrece una visión completa. La combinación de todas ellas, centralizada en una plataforma de correlación, permite detectar anomalías que serían invisibles si se analizaran de forma aislada: por ejemplo, un volumen de tráfico inusual hacia un destino externo que coincide con un proceso no autorizado en un endpoint y una regla de firewall modificada sin aprobación. Esa correlación es la base del monitoreo de seguridad y telemetría efectivo.
Criterios de priorización de visibilidad por criticidad y exposición
No todos los activos merecen el mismo nivel de observabilidad. Priorizar qué monitorizar con mayor intensidad es una decisión estratégica que debe combinar dos dimensiones: la criticidad del activo para el negocio y su nivel de exposición a amenazas externas o internas.
Los activos críticos con alta exposición —servidores de acceso remoto, sistemas de autenticación, bases de datos con información sensible, equipos de red perimetrales— deben recibir monitorización en tiempo real y alertas inmediatas ante cualquier desviación. Los activos de criticidad media con exposición controlada pueden gestionarse con revisiones periódicas. Esta segmentación de la visibilidad permite concentrar los recursos de análisis donde el impacto potencial es mayor, evitando la fatiga de alertas que paraliza a los equipos de seguridad cuando todo tiene el mismo nivel de urgencia.
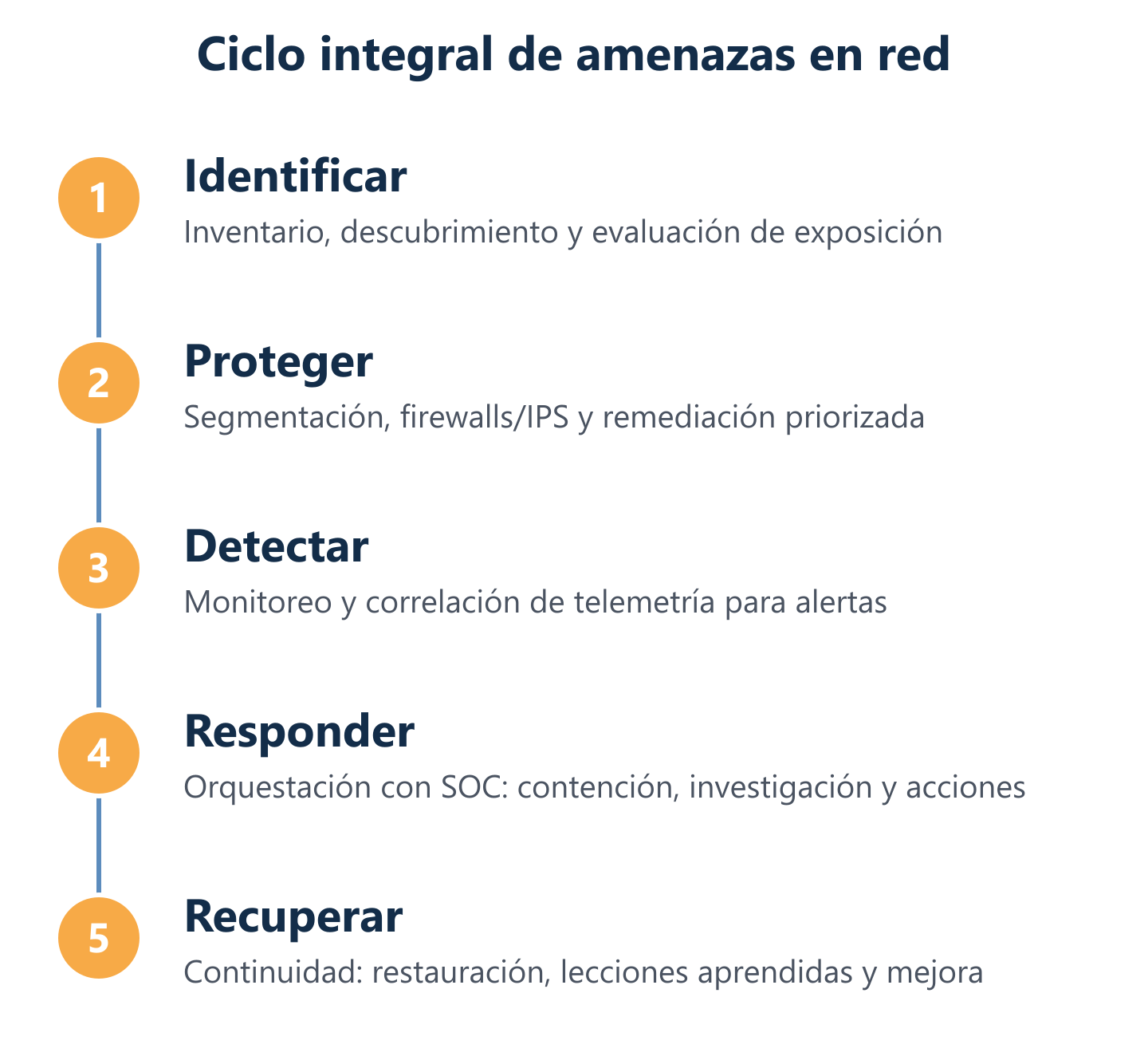
Ciclo operativo completo: vulnerabilidades, controles, detección y respuesta
Una vez establecida la visibilidad, el ciclo operativo de la gestión integral de amenazas de red se articula en cuatro fases que se retroalimentan continuamente. No son etapas secuenciales que se ejecutan una vez al año; son procesos paralelos que operan a distintas cadencias y se informan mutuamente.
En Impulso Tecnológico integramos control perimetral y protección en profundidad apoyándonos en tecnologías de nivel enterprise: firewalls de nueva generación de Fortinet y Sophos para el control del tráfico, protección avanzada de endpoints para contener amenazas que superan el perímetro, y Veeam para garantizar la resiliencia mediante copias de seguridad y recuperación ante desastres. Todo ello operado con acompañamiento técnico remoto y SLA definidos: respuesta en menos de cuatro horas para incidencias críticas y en menos de ocho horas para incidencias estándar.
- Gestión de vulnerabilidades: escaneo regular, priorización por riesgo basada en criticidad del activo y explotabilidad real, y remediación controlada con ventanas de mantenimiento definidas.
- Controles de seguridad de red: segmentación de red, firewalls e IPS configurados con políticas de mínimo privilegio, y arquitectura Zero Trust para accesos remotos y entre segmentos.
- Detección y monitoreo: correlación de telemetría, análisis de comportamiento y alertas priorizadas para reducir el tiempo medio de detección.
- Respuesta y recuperación: playbooks de respuesta ante incidentes, orquestación de respuesta automatizada para contención rápida, y planes de recuperación ante ransomware y otros escenarios de alto impacto.
- Mejora continua: revisión post-incidente, actualización del inventario y ajuste de controles basado en las lecciones aprendidas y en la inteligencia de amenazas actualizada.
Gestión de vulnerabilidades de red: de escaneo a remediación
El escaneo de vulnerabilidades es el punto de partida, no el destino. Un escaneo sin priorización genera listas interminables de hallazgos que ningún equipo puede atender en tiempo razonable. La clave está en la priorización por riesgo: combinar la puntuación CVSS de cada vulnerabilidad con el contexto del activo afectado (criticidad para el negocio, exposición real y existencia de exploit conocido) para determinar qué se remedia primero.
En Impulso Tecnológico realizamos auditorías de infraestructura trimestrales que identifican vulnerabilidades emergentes antes de que se conviertan en incidentes. La remediación se planifica con ventanas de mantenimiento que minimizan el impacto operativo: los parches críticos en sistemas expuestos se aplican en horas; los de menor riesgo se agrupan en ciclos regulares. Este enfoque, detallado también en nuestra guía de auditoría de redes informáticas, reduce la ventana de explotación sin interrumpir la operación.
Seguridad de red como control: segmentación, IPS/firewalls y Zero Trust
Los controles de seguridad de red no son un sustituto de la gestión de vulnerabilidades: son el mecanismo que reduce la probabilidad de explotación mientras los parches se despliegan y que limita el daño si un atacante consigue entrar. La segmentación de red divide la infraestructura en zonas con políticas de comunicación estrictas, de modo que un dispositivo comprometido no puede moverse libremente hacia sistemas críticos.
Los firewalls de nueva generación (NGFW) de Fortinet y Sophos, que desplegamos en Impulso Tecnológico, combinan inspección profunda de paquetes, prevención de intrusiones (IPS) y control de aplicaciones en un único punto de control. La arquitectura Zero Trust complementa estos controles al exigir verificación continua de identidad y contexto para cada acceso, independientemente de si el usuario está dentro o fuera de la red corporativa. Puedes profundizar en este enfoque en nuestro artículo sobre instalación de firewall para redes.
Detección y respuesta coordinada: SOC, automatización e integración de datos
La detección eficaz depende de la calidad de la correlación de datos, no del volumen de alertas. Un SOC que recibe miles de alertas sin contexto acaba priorizando mal o ignorando señales críticas. La automatización —mediante playbooks que ejecutan acciones de contención predefinidas ante patrones conocidos— libera al equipo humano para investigar los incidentes que realmente requieren análisis experto.
La integración de datos de seguridad (logs de red, eventos de endpoint, alertas de vulnerabilidades, inteligencia de amenazas externa) en una plataforma centralizada es el requisito técnico previo para que esa automatización funcione. En entornos donde Impulso Tecnológico opera como proveedor gestionado único, esa integración elimina los silos de información entre herramientas y permite que la orquestación de respuesta actúe sobre datos coherentes y actualizados, reduciendo el tiempo entre detección y contención a minutos en los escenarios más críticos.
Conectar visibilidad, controles y operación en un único ciclo transforma la gestión integral de amenazas de red de un concepto abstracto en una ventaja operativa medible: menos tiempo de exposición, respuestas más rápidas y una capacidad real de recuperación ante incidentes graves. Las organizaciones que implementan este modelo dejan de gestionar herramientas y empiezan a gestionar riesgos.
Si tu organización opera con infraestructura distribuida, entornos cloud o equipos remotos y quieres evaluar el nivel de madurez de tu programa actual, el primer paso es una revisión estructurada de tus activos, controles y capacidades de detección. En Impulso Tecnológico podemos acompañarte en ese proceso desde el diagnóstico inicial hasta la operación continua, con un modelo de servicio gestionado flexible y sin sorpresas en los costes. También puedes consultar nuestro artículo sobre cómo desarrollar un plan de seguridad informática para complementar esta guía con una hoja de ruta estructurada.
