
A cloud services migration success story combines three elements: a clear before-and-after comparison, measurable outcomes tied to business objectives, and documented evidence that security, continuity, and governance were maintained throughout the process. Without all three, it is a project report—not a success story.
Organisations that treat cloud migration as a one-off technical task consistently underestimate the operational risk involved. Workloads move, but monitoring gaps, uncontrolled costs, and compliance blind spots follow them into the new environment. The result is a migration that technically completes on schedule yet fails to deliver the stability and efficiency that justified the investment in the first place.
The blueprint in this article addresses that gap directly. It covers how to define success criteria before the first workload moves, how to choose the right migration approach for your constraints, and how to build governance and risk controls that protect continuity at every phase. It also shows how to translate execution details—infrastructure as code, RPO/RTO planning, phased rollouts—into the kind of evidence that earns stakeholder confidence. At Impulso Tecnológico, this is the model we apply when supporting clients through cloud transitions, combining managed services, proactive monitoring, and SLA-backed assistance to keep operations stable while improvements are delivered.
What "success" means in a Cloud Services Migration (beyond cost savings)
Cost reduction is the metric most frequently cited in cloud migration business cases, yet it is rarely sufficient on its own to demonstrate that a migration succeeded. Organisations that report only infrastructure spend reductions often discover, months later, that performance degraded, security posture weakened, or recovery objectives were never validated in the new environment. A credible cloud services migration success story requires a broader set of criteria—ones that stakeholders across IT, finance, legal, and operations can each recognise as relevant to their concerns.
The table below maps the four primary success dimensions to the specific evidence you should collect and report:
| Success Dimension | What to Measure | Evidence to Report | Common Failure Signal |
|---|---|---|---|
| Cost Control | Monthly cloud spend vs. on-premises baseline; reserved vs. on-demand ratio | Spend dashboards, tagging coverage, budget alerts triggered | Untagged resources; runaway on-demand instances |
| Performance | Application response times, throughput, availability SLA adherence | Before/after latency benchmarks; uptime reports | Latency regression post-migration; SLA breaches |
| Security & Compliance | Policy violations, encryption coverage, audit log completeness | Compliance scan results; penetration test outcomes; audit trail exports | Open ports; unencrypted storage; missing audit logs |
| Continuity (RPO/RTO) | Recovery Point Objective and Recovery Time Objective vs. targets | DR test results; backup job success rates; failover timelines | Untested DR plans; backup failures discovered post-incident |
At Impulso Tecnológico, our managed services model is designed so that continuity and monitoring are active from the moment migration begins—not added as an afterthought once workloads have moved. This means the evidence needed for a strong success story is being collected throughout the project, not reconstructed afterwards.
Success criteria: cost control, performance, and operational continuity
A balanced scorecard approach prevents the common mistake of optimising one dimension at the expense of others. Cost savings achieved by eliminating redundant infrastructure mean little if application performance degrades and support tickets spike. Equally, a performance improvement that doubles cloud spend without governance controls will erode confidence in the migration decision within one budget cycle.
Operational continuity deserves particular attention. During migration, the risk window for incidents is wider than in steady state. Monitoring coverage must be established before workloads move, not configured reactively after the first outage. Define your RPO and RTO targets at the assessment stage, validate them with a DR test before go-live, and report the results as part of your success evidence. This is the difference between claiming continuity and proving it.
Security and compliance evidence: audit readiness and protection controls
Security posture must be measurable before and after migration to appear credibly in a success story. Baseline the current state: document open vulnerabilities, encryption gaps, access control weaknesses, and audit log coverage. Then define target outcomes—specific controls that will be in place in the cloud environment—and verify them with evidence rather than assertions.
For organisations operating under frameworks such as SOC 2, ISO 27001, or GDPR, audit readiness is a concrete deliverable. This means encryption at rest and in transit is enforced and documented, identity and access management policies are applied consistently, and audit trails are complete and exportable. Tools such as Sophos and Fortinet—both part of the Impulso Tecnológico partner stack—provide endpoint and network-level controls that can be aligned to compliance requirements from day one of the cloud environment, rather than retrofitted later.
Migration success criteria checklist: RPO/RTO, KPIs, and reporting cadence
Establishing a reporting cadence before migration begins forces the team to agree on what success looks like in measurable terms. The following checklist covers the signals that distinguish a well-governed migration from one that simply completed:
- RPO defined and tested: maximum acceptable data loss validated with a backup restore test, not assumed from vendor documentation.
- RTO defined and tested: recovery time objective validated with a failover exercise before production go-live.
- Cost KPIs tracked from day one: tagging policy enforced, budget alerts active, and spend reviewed weekly during migration and monthly post-stabilisation.
- Performance baselines captured: application response times, throughput, and error rates recorded in the source environment and compared post-migration.
- Governance signals documented: change log completeness, IaC coverage percentage, and number of unplanned changes during migration window.
- Incident and rollback record: any rollback executed during migration documented with root cause and resolution time.
This checklist also provides the raw material for the stakeholder narrative described later in this article.

Choosing the migration approach: lift-and-shift vs modernisation vs hybrid
The choice of migration strategy shapes every subsequent decision: timeline, cost profile, skills required, risk exposure, and the story you will be able to tell at the end. There is no universally correct answer, but there is a structured way to reach the right one for your organisation's constraints.
The three primary approaches—lift-and-shift (rehost), modernisation (re-architect or re-platform), and hybrid—each carry distinct trade-offs that must be evaluated against your operational reality, not against vendor marketing materials. At Impulso Tecnológico, we approach this decision by first understanding the client's actual dependencies, compliance requirements, and tolerance for disruption, rather than applying a generic template. Centralising management under one partner also means the trade-offs are evaluated holistically—infrastructure, security, backup, and support are considered together, not in isolation.
The decision framework below structures the evaluation across the criteria that matter most:
- Assess workload criticality and dependency mapping: identify which applications are tightly coupled, which carry compliance obligations, and which can move independently.
- Evaluate time-to-cloud pressure: if speed is the primary constraint, lift-and-shift reduces disruption but may carry technical debt into the cloud environment.
- Quantify skills availability: modernisation requires cloud-native expertise; if that capability is not available internally, a managed partner reduces the skills gap risk.
- Map compliance and data residency requirements: some workloads cannot move until data residency and sovereignty controls are confirmed in the target environment.
- Define the acceptable disruption window: phased hybrid migrations allow critical workloads to remain on-premises while less sensitive systems move first, reducing the blast radius of any migration incident.
- Agree on the long-term operating model: the chosen approach must be supportable in steady state, not just during the migration project.
Decision framework: when to choose lift-and-shift, modernisation, or hybrid
Lift-and-shift is the appropriate choice when speed of migration outweighs the need for architectural improvement, or when applications are stable and the organisation lacks the internal capacity to re-architect while maintaining operations. The risk is that technical debt migrates alongside the workload. Poorly optimised applications running on oversized virtual machines in the cloud often cost more than the equivalent on-premises setup, particularly if reserved capacity planning is not applied from the outset.
Modernisation—re-platforming to managed services or re-architecting to cloud-native patterns—delivers better long-term efficiency and agility, but requires sequencing. Attempting to modernise every workload simultaneously is a reliable path to cost overruns and delayed go-live dates. The pragmatic approach is to modernise selectively: prioritise workloads where cloud-native capabilities (elasticity, managed databases, serverless functions) deliver measurable operational benefit.
Risk trade-offs: downtime, data integrity, technical debt, and skills gaps
Every migration approach carries a specific risk profile that must be acknowledged in the project plan and addressed in the success story. Lift-and-shift minimises downtime risk during the migration window but introduces long-term operational risk if the underlying architecture is not revisited. Modernisation reduces long-term technical debt but increases the complexity and duration of the migration itself, which extends the window during which both environments must be maintained in parallel.
Skills gaps are consistently underestimated. A team proficient in on-premises infrastructure management may lack the cloud governance, IaC, and cost optimisation skills needed to operate effectively in the new environment. This is where a managed services partner adds concrete value—not only during migration, but in the steady-state operation that follows. Veeam-based backup and recovery practices, for example, can be carried across from on-premises to cloud environments with consistent policy coverage, reducing one category of operational risk regardless of the migration approach chosen.
A story-led approach: turning strategy choices into stakeholder buy-in
The hybrid approach—moving some workloads immediately via lift-and-shift while modernising others in a subsequent phase—is frequently the most defensible choice when presenting to stakeholders. It demonstrates pragmatism: the organisation captures early cloud benefits without betting the entire operation on a single large-scale modernisation effort.
For stakeholder communication, frame the hybrid strategy as a sequenced programme rather than a compromise. Phase one delivers speed and early cost evidence. Phase two delivers architectural improvement and long-term efficiency. Each phase has its own success criteria, its own reporting cadence, and its own story. This structure also makes it easier to secure continued investment: stakeholders can see phase one results before committing to phase two scope. For organisations working with Impulso Tecnológico, our flexible monthly contracting model supports this phased approach—costs are controlled at each stage, and scope can be adjusted as the programme progresses without renegotiating long-term contracts.
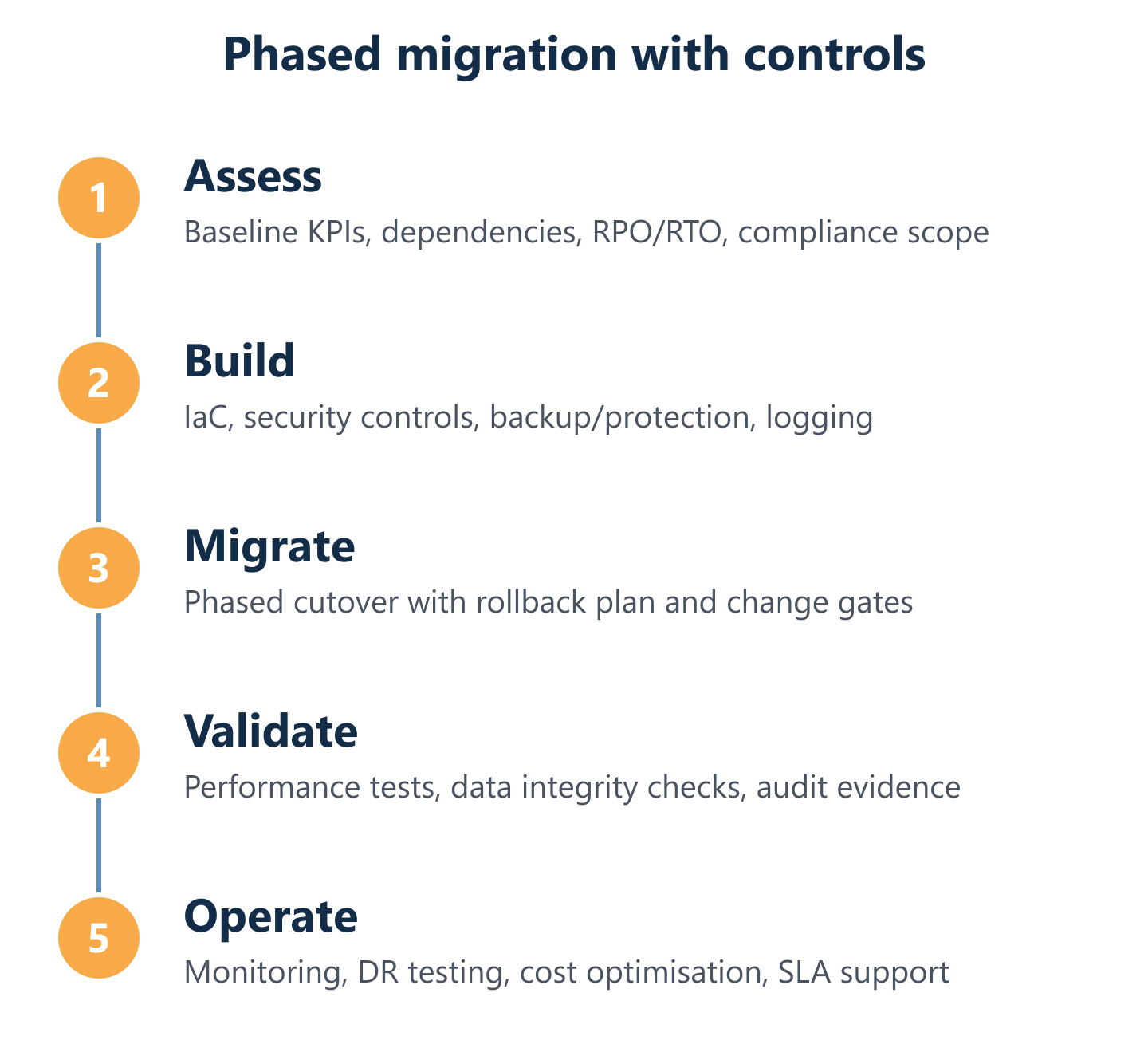
The migration blueprint: phases, governance, and risk controls
A migration blueprint that stops at workload movement is incomplete. The operational model that runs in the cloud environment after migration determines whether the investment delivers its intended value. Governance, monitoring, backup routines, and change management must be designed before the first workload moves—not configured reactively once issues surface.
The following elements are non-negotiable components of a well-governed migration blueprint:
- Dependency mapping completed before planning: undocumented dependencies between applications are the most common cause of unexpected downtime during migration.
- Entry and exit criteria defined for each phase: each migration wave should have explicit conditions that must be met before the next wave begins.
- Rollback plan documented and tested: not every rollback is a failure—having a tested rollback procedure is a governance signal, not a sign of weakness.
- Infrastructure as code (IaC) coverage from day one: environments built manually are difficult to audit, replicate, or recover consistently.
- Cost guardrails active before go-live: budget alerts, tagging policies, and spending limits must be configured in the target environment before workloads arrive.
- Monitoring and alerting validated pre-migration: confirm that observability tools are capturing the right signals in the new environment before cutting over production traffic.
- Backup and DR readiness confirmed: backup jobs running and tested; DR runbook documented and rehearsed.
At Impulso Tecnológico, our managed services structure means these controls are embedded in how we deliver projects—proactive monitoring, SLA-backed support, and backup/protection practices using tools including Veeam and Microsoft Azure-native capabilities are operational from the start of the migration window, not added once stabilisation is declared.
Phased execution plan: assessment, build, migrate, validate, and operate
A five-phase execution model provides the structure needed to manage risk across the full migration lifecycle. The assessment phase produces the dependency map, workload inventory, and baseline performance and security measurements that everything else depends on. The build phase establishes the target environment: network architecture, identity and access management, IaC templates, monitoring configuration, and backup policies—all validated before any production workload moves. The migrate phase executes workload movement in waves, starting with non-critical systems to validate tooling and process before touching production. The validate phase confirms that performance, security, and continuity targets are met, including a DR test against the documented RPO/RTO. The operate phase transitions to steady-state managed services, with incident management, cost optimisation reviews, and continuous compliance monitoring embedded in the operating model.
Governance and controls: IaC, change management, and cost guardrails
Infrastructure as code is the governance foundation that makes cloud environments auditable, reproducible, and recoverable. When every resource is defined in version-controlled templates—whether using Terraform, Bicep for Azure, or equivalent tooling—the environment can be rebuilt consistently, changes are tracked, and drift from the approved configuration is detectable. This matters both operationally and for compliance: an auditor asking how a specific control was implemented can be shown the code, not just a verbal description.
Change management during migration must be formal. Every change to the production environment—whether in the source or target—should be logged, approved, and reversible. Cost guardrails are equally important: resource tagging policies, budget alerts at defined thresholds, and regular spend reviews prevent the cost overruns that undermine confidence in cloud migration decisions. These are not bureaucratic controls; they are the evidence base for the success story.
Operational readiness: monitoring, backup routines, and DR testing
Operational readiness is the point at which a migration project becomes a sustainable operating model. Three capabilities must be confirmed before declaring migration complete. First, monitoring coverage: every workload in the cloud environment must be observed for availability, performance, and security events, with alerts routed to the team responsible for response. Second, backup routines: automated, scheduled backups with verified restore capability—not just backup job completion logs. Veeam, for example, provides immutable backup options that protect against ransomware and accidental deletion, which is particularly relevant when migrating to cloud environments where access controls are being reconfigured. Third, DR testing: a documented failover exercise, executed against the live cloud environment, that confirms the RPO and RTO targets defined at the assessment stage are achievable in practice. Without this test, continuity claims in the success story are unverified assertions.
A cloud services migration success story is not written at the end of the project—it is built throughout it, in the decisions made at each phase, the controls put in place before workloads move, and the evidence collected from day one. The organisations that tell the most credible migration stories are those that treated governance, security, and continuity as deliverables alongside the technical migration itself. If your next migration follows the blueprint outlined here, the metrics will reflect that discipline. For organisations that want a managed services partner to support that process—from assessment through to steady-state operation—explore our cloud services for businesses or review our complete guide to cloud solutions implementation to understand how Impulso Tecnológico structures this work in practice.
