
IT network management for businesses is the structured discipline of administering, monitoring, securing, and continuously improving a company's network infrastructure to keep operations reliable, productive, and protected. It covers everything from physical cabling and device configuration to real-time performance monitoring, fault resolution, and security enforcement.
Most organisations discover the gaps in their network management only after an outage, a security incident, or a compliance audit. By that point, the cost — in lost productivity, emergency support fees, and reputational risk — is already significant. The reactive model simply does not scale as networks grow more complex with remote workers, cloud workloads, and multi-site connectivity.
A structured approach changes that equation. When network management is treated as an ongoing operational discipline rather than a break-fix service, businesses gain predictable uptime, faster fault resolution, and a security posture that holds up under scrutiny. At Impulso Tecnológico, we have spent over 25 years building and managing these environments for companies across Spain, Portugal, and beyond — and the difference between managed and unmanaged networks is measurable from the first month.
What IT Network Management Means for Businesses (Beyond "Keeping Networks Running")
Network management is not a single tool or a helpdesk ticket queue. For businesses, it is an end-to-end service discipline that spans five interconnected domains: administration (policies, user access, supplier and budget management), operations (monitoring, fault detection, incident response), maintenance (updates, patching, hardware lifecycle), performance monitoring (KPIs, baselines, capacity planning), and security (layered controls, compliance, threat remediation). Each domain feeds the others — a poorly maintained device creates a performance bottleneck; an unmonitored segment becomes a security blind spot.
Impulso Tecnológico approaches this as an external IT department: a partner that plans, deploys, and manages the network and surrounding systems so that operations remain reliable, secure, and scalable. This matters because the business outcomes at stake are not abstract — they include uptime for revenue-generating systems, productivity for distributed teams, and risk reduction for regulatory compliance.
| Management Domain | What It Covers | Business Outcome Protected |
|---|---|---|
| Administration | Policies, user access, IT supplier and budget management | Cost control, governance, vendor accountability |
| Operations | Monitoring, fault detection, incident response | Uptime, mean time to repair (MTTR), service continuity |
| Maintenance | Firmware/OS updates, patching, hardware lifecycle | Vulnerability reduction, hardware reliability |
| Performance Monitoring | KPIs, baselines, capacity planning, traffic analysis | Productivity, application performance, scalability |
| Security | Layered controls, access management, compliance, threat remediation | Data protection, regulatory compliance, incident prevention |
Business outcomes network management should protect
The right frame for evaluating network management is not "are my switches online?" but "are my business operations protected?". Three outcomes sit at the centre of every well-run network programme. First, uptime: every minute of unplanned downtime has a direct cost in lost transactions, delayed production, or idle staff. Second, productivity: slow or unreliable connectivity degrades application performance and frustrates distributed teams. Third, risk reduction: an unpatched device or misconfigured firewall rule is a liability that can result in data breaches, regulatory fines under GDPR, or ransomware incidents. A business-first scope means every network management decision is evaluated against these outcomes, not just against device-level metrics.
The service lifecycle: from policies to ongoing support
Effective IT network management follows a continuous lifecycle rather than a project-based model. It begins with planning: defining system usage policies, mapping business requirements to network design, and aligning specifications with budget. Deployment follows — physical infrastructure (structured cabling, switches, firewalls, wireless access points) is installed and configured to a documented standard. Once live, the network enters an operate-and-improve cycle: monitoring tools collect telemetry, alerts trigger investigation, and controlled changes are applied through a documented change management process. Impulso Tecnológico covers this full lifecycle for clients — from initial network and systems deployment and migration through to audits, ongoing managed support, and structured cabling projects that provide the certified physical layer on which everything else depends.
Common gaps when networks are managed reactively
Reactive network management — fixing problems after they occur — consistently produces the same failure patterns. Configuration drift accumulates as undocumented changes are applied under pressure, making the environment progressively harder to troubleshoot. Security patches are delayed because there is no scheduled maintenance window, leaving known vulnerabilities exposed for weeks or months. Performance baselines are never established, so degradation goes unnoticed until users complain. And when an incident does occur, the absence of logs, change records, or network diagrams turns a one-hour fix into a multi-day investigation. These are not edge cases — they are the predictable result of treating security and performance as one-off tasks rather than ongoing operational disciplines with clear ownership and measurable targets.

The Core Capabilities: Provisioning, Configuration, Security and Measurement
Four capabilities form the operational spine of any enterprise network management framework. When all four are functioning well, the network becomes a managed, predictable asset. When any one is missing, the others degrade. Impulso Tecnológico's approach integrates all four into a single service model, combining certified physical infrastructure (structured cabling for data, voice, and fibre optic), layered security controls, and ongoing maintenance to minimise downtime.
- Provisioning: Deploying new devices, users, and services to a documented standard — including physical cabling, switch configuration, VLAN assignment, and IP address management — so that every addition to the network is consistent and traceable.
- Configuration management: Maintaining a current, version-controlled record of every device's configuration, with a formal change control process that requires approval, testing, and rollback capability before any change reaches production.
- Security operations: Applying layered defences across the network perimeter (firewall, gateway, web and email filtering, intrusion prevention), endpoints (antivirus, personal firewall, spyware removal), and access controls (VPN, strong authentication, encryption, access ID management), supported by regular patch management, vulnerability assessments, and penetration testing.
- Measurement and reporting: Collecting real-time and historical KPIs (bandwidth utilisation, latency, packet loss, error rates, device availability) against established baselines, and translating alerts into prioritised actions and trend reports that inform capacity planning and security decisions.
Provisioning and configuration management (safe change control)
The majority of network outages are caused by human error during change events — a misconfigured access control list, an incorrect VLAN assignment, or a firmware update applied without a rollback plan. Safe provisioning and configuration management eliminates most of these risks through process discipline. Every device should have a baseline configuration stored in a version-controlled repository. Changes must follow a documented workflow: request, impact assessment, approval, scheduled maintenance window, implementation, verification, and documentation update. For multi-site or enterprise environments, this process should be enforced by a network change management tool rather than relying on individual engineers' habits. Impulso Tecnológico applies this discipline from the physical layer up — certified structured cabling installations create a documented, stable foundation that reduces ambiguity when troubleshooting or expanding the network later.
Layered network and endpoint security operations
A single firewall is not a security strategy. Effective hybrid network security operations require controls at multiple layers simultaneously. At the network perimeter, firewall and gateway policies, secure web filtering, secure email filtering, and intrusion prevention systems block the majority of inbound threats before they reach internal systems. At the endpoint layer, antivirus, personal firewall, and spyware removal tools address threats that bypass the perimeter. Across both layers, patch and vulnerability management closes known weaknesses on a scheduled basis, while periodic penetration testing validates that controls are working as intended. Access management — strong password policies, VPNs for remote users, encryption for sensitive data, and access ID management — ensures that authorised users are the only ones who can reach critical systems. Impulso Tecnológico deploys and manages these controls using technologies from Sophos, Fortinet, and Veeam, selected to match each client's environment and risk profile.
Measurement: KPIs, baselines, and actionable reporting
Network monitoring KPIs only deliver value when they are tied to business thresholds rather than arbitrary technical limits. The first step is establishing baselines: what does normal bandwidth utilisation look like on a Monday morning versus a Friday afternoon? What is the expected round-trip latency between the main office and a cloud-hosted ERP system? Once baselines exist, alerts can be calibrated to flag genuine anomalies rather than generating noise. Key metrics to track include device availability (uptime percentage per critical device), interface utilisation (to detect congestion before it affects users), error rates (indicative of physical layer or configuration issues), and latency and packet loss (which directly affect application performance). Reporting should translate these metrics into decisions: which segment needs capacity expansion, which device is approaching end-of-life, and which alert pattern suggests a security incident in progress.
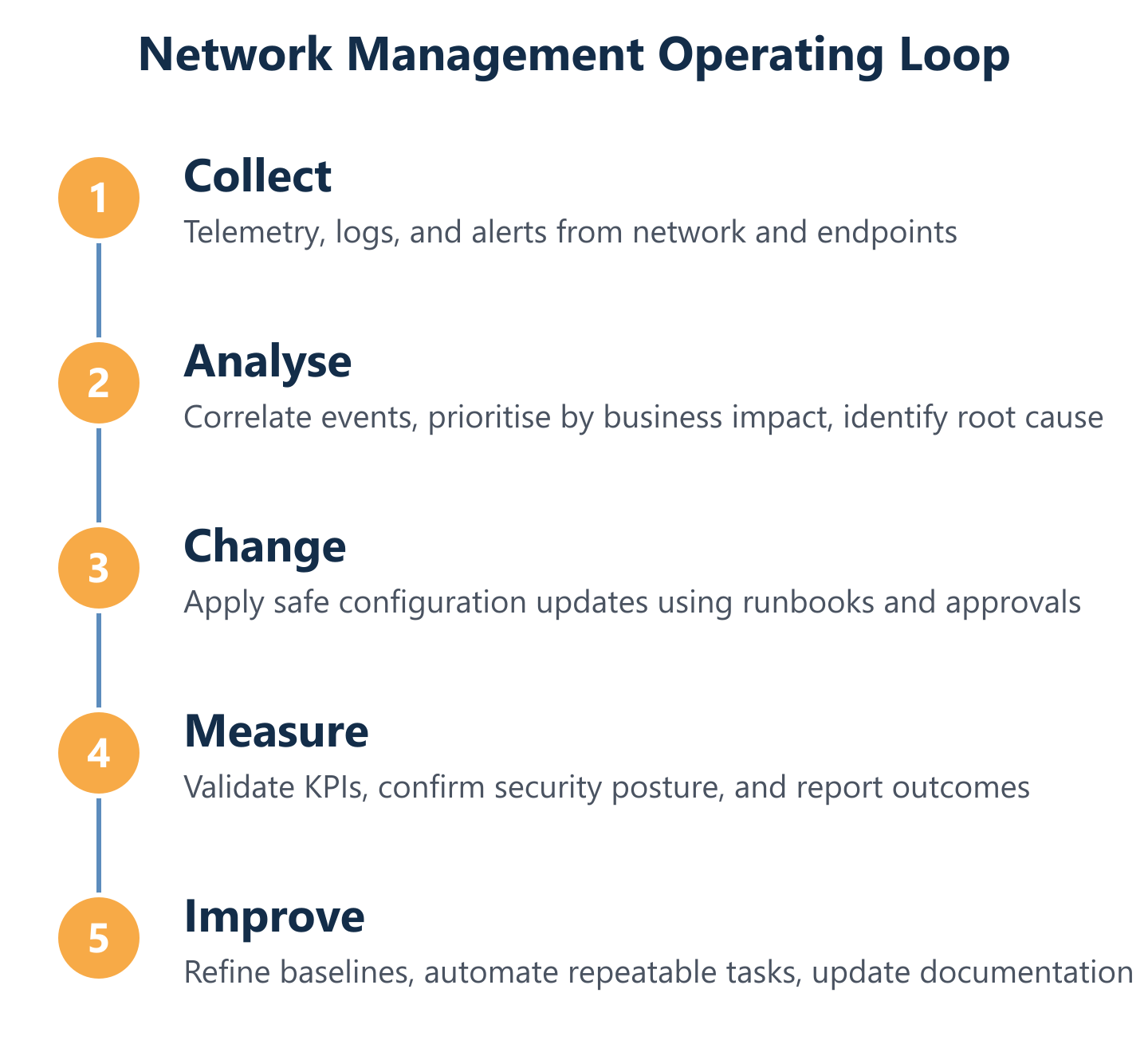
How Network Management Works in Practice (Data Collection → Analysis → Change)
The operational loop that underpins reliable network management has three stages: collect, analyse, and act. In the collection stage, monitoring agents and protocols (SNMP, NetFlow, syslog, ICMP, and increasingly streaming telemetry) gather real-time data from every managed device and send it to a central management platform. In the analysis stage, that data is correlated against baselines and alert thresholds — either by engineers reviewing dashboards or by automated rules that surface prioritised incidents. In the action stage, the team responds: either resolving a fault, applying a configuration change through the change control process, or escalating to a specialist.
What makes this loop effective in practice is not the tools alone — it is the combination of clear escalation paths, documented runbooks, and a delivery model that matches the organisation's capacity. Impulso Tecnológico supports this operational loop from Spain on-site and remotely for clients across Europe, Asia, and America, combining consultancy, systems monitoring, and managed services to ensure that the loop runs consistently and that resolution happens within agreed timeframes.
- Centralised visibility: All devices, links, and services feed into a single monitoring platform — no blind spots in remote offices or cloud-connected segments.
- Alert triage: Not every alert requires the same response; severity classification ensures that business-critical faults are addressed first.
- Documented runbooks: Common fault scenarios have pre-approved response procedures, reducing mean time to repair (MTTR) significantly.
- Change control integration: Fixes that require configuration changes follow the same approval workflow as planned changes, preventing reactive modifications from creating new problems.
- Post-incident review: Every significant fault generates a root-cause analysis that feeds back into monitoring thresholds, architecture decisions, and maintenance schedules.
From monitoring to troubleshooting: what to detect first
When setting up network monitoring for the first time — or auditing an existing setup — prioritise visibility in this order. Start with device availability: know immediately when a core switch, firewall, or router goes offline. Add interface utilisation on uplinks and WAN connections next, since congestion here affects every user simultaneously. Then instrument latency and packet loss on paths to critical applications (ERP, VoIP, cloud services), because degraded application performance is often the first symptom users report. Security event logging — firewall denies, authentication failures, IDS alerts — should be collected in parallel from day one, even if full analysis comes later. Tools such as ManageEngine OpManager, Domotz, or equivalent platforms can aggregate these signals centrally; the choice of tool matters less than ensuring complete coverage of the devices and segments that carry business-critical traffic. For clients working with Impulso Tecnológico, our network infrastructure maintenance service includes this monitoring baseline as a standard component.
Change and configuration workflows that prevent outages
The network change management best practice that consistently reduces outage frequency is simple to describe but requires discipline to execute: no undocumented change reaches a production device. In practice, this means every change — from updating a firewall rule to replacing a switch — follows a written request that includes a description of the change, the business reason, the expected impact, a test plan, and a rollback procedure. Changes are scheduled during low-traffic windows where possible. After implementation, the engineer verifies that the intended outcome was achieved and that no unintended side effects occurred, then updates the configuration repository and closes the change record. This workflow applies equally to emergency changes, which are documented retrospectively if time pressure prevents prior approval. Organisations that adopt this discipline typically see a measurable reduction in change-related incidents within the first quarter of implementation.
Hybrid and remote work considerations for secure connectivity
Hybrid networks — combining on-premises infrastructure, cloud workloads, remote workers, and potentially IoT or edge devices — introduce management complexity that purely on-premises networks do not face. The core challenges are visibility (personally owned or remote devices may not be managed by corporate tools), consistent policy enforcement (a firewall rule applied on-premises may not extend to cloud-hosted segments without explicit configuration), and secure remote access (VPNs must be properly sized, monitored, and patched). For remote workers specifically, endpoint security controls become as important as network-level controls, since the corporate perimeter no longer exists in the traditional sense. Impulso Tecnológico addresses this through a combination of VPN management, secure remote access configuration, endpoint protection, and identity and access management — ensuring that remote connectivity supports productivity without creating unmonitored entry points into the corporate network. Our corporate network service covers these hybrid scenarios as a standard part of the engagement.
A network management blueprint is only as valuable as the plan that puts it into action. The practical path forward follows a clear sequence: audit your current environment to identify monitoring gaps and configuration risks; establish performance and security baselines so that future deviations are immediately visible; implement layered security controls across the perimeter, endpoints, and access layer; introduce a formal change management process; and define measurable targets — uptime thresholds, MTTR targets, patch compliance rates — that give your team clear ownership. Whether you build this capability internally, adopt a NOC-as-a-service model, or partner with a managed IT provider, the goal is the same: a network that supports your business reliably, adapts as you grow, and does not become a liability. If you would like to discuss how this blueprint applies to your specific environment, Impulso Tecnológico is ready to help.
