
La gestión de redes IT para empresas abarca el conjunto de procesos, herramientas y políticas que permiten aprovisionar, monitorizar, proteger y mantener la infraestructura de red para garantizar disponibilidad, rendimiento y seguridad de forma continua. No es solo conectividad: es operación controlada.
Muchas organizaciones descubren tarde que su red era el eslabón más débil. Un switch sin actualizar, un firewall mal configurado o la ausencia de monitorización activa pueden derivar en interrupciones de servicio, brechas de seguridad o pérdidas de datos que ningún backup tardío puede compensar del todo. El problema no es la tecnología; es la falta de un marco operativo que conecte seguridad, rendimiento y continuidad en un único proceso gestionado.
Esta guía cubre el marco completo de la gestión de redes IT: desde el aprovisionamiento y la configuración hasta la arquitectura de un NOC, los criterios para elegir herramientas o un servicio gestionado (MSP), y un plan de implementación por fases. El resultado: pasar de una gestión reactiva a una operación proactiva donde la red respalda el negocio en lugar de frenarlo.
Qué incluye la gestión de redes IT para empresas (marco end-to-end)
Gestionar una red empresarial va mucho más allá de mantener los switches encendidos. El marco end-to-end comprende cinco dominios interconectados: aprovisionamiento (incorporar dispositivos y servicios a la red con configuración válida), gestión de configuración (mantener el estado deseado y controlar cambios), monitoreo y observabilidad (recopilar métricas, logs y telemetría para detectar anomalías), seguridad y resiliencia (reducir superficie de ataque, gestionar fallos y garantizar la recuperación), y operación y mantenimiento continuo (actualizaciones, auditorías y gestión del ciclo de vida).
En Impulso Tecnológico, tras más de 25 años gestionando infraestructuras IT, hemos comprobado que las empresas que tratan estos dominios de forma aislada acumulan puntos ciegos. Nuestra metodología conecta los cinco en un servicio integral con SLA garantizados, usando tecnologías como Fortinet y Cisco para redes, Sophos para seguridad de endpoint y perímetro, y Veeam para continuidad. El objetivo es reducir la superficie de ataque, corregir vulnerabilidades de forma sistemática y mantener la disponibilidad con procesos de backup y recuperación ante incidentes probados.
| Dominio | Alcance mínimo | Alcance recomendado | Riesgo si se omite |
|---|---|---|---|
| Aprovisionamiento | Configuración manual de dispositivos | Plantillas y automatización de configuración | Errores humanos y tiempo de despliegue elevado |
| Gestión de configuración | Documentación estática | Control de versiones y estado deseado automatizado | Deriva de configuración y fallos difíciles de rastrear |
| Monitoreo y observabilidad | Ping y disponibilidad básica | Telemetría, logs, métricas de rendimiento y alertas inteligentes | Detección tardía de fallos y cuellos de botella |
| Seguridad y resiliencia | Firewall perimetral y antivirus | Defensa en profundidad: IDS/IPS, segmentación, VPN, gestión de identidades | Brechas laterales y tiempo de recuperación elevado |
| Operación y mantenimiento | Actualizaciones reactivas | Mantenimiento preventivo, auditorías periódicas y gestión del ciclo de vida | Vulnerabilidades no parcheadas y obsolescencia técnica |
Aprovisionamiento y configuración: de la intención a la red operativa
El aprovisionamiento define cómo un dispositivo entra en producción con la configuración correcta desde el primer momento. Sin un proceso formal, cada despliegue es una fuente potencial de errores: VLANs mal asignadas, contraseñas por defecto no cambiadas o políticas de acceso inconsistentes. La gestión de cambios de red añade la capa de control: ninguna modificación debe aplicarse sin registro, aprobación y posibilidad de reversión.
En la práctica, esto implica mantener plantillas de configuración por tipo de dispositivo, controlar versiones de firmware y documentar el estado deseado de cada elemento de red. Herramientas como Cisco DNA Center o las capacidades de gestión centralizada de Fortinet permiten automatizar este ciclo. En Impulso Tecnológico aplicamos este enfoque tanto en despliegues nuevos como en auditorías de redes existentes, identificando desviaciones respecto al estado deseado antes de que se conviertan en incidentes.
Monitoreo y observabilidad: métricas, logs y telemetría accionables
La monitorización de redes tradicional se limitaba a comprobar si un dispositivo respondía al ping. La observabilidad de red va más lejos: combina métricas de rendimiento (latencia, pérdida de paquetes, utilización de interfaces), logs de eventos y telemetría de flujo (NetFlow, sFlow) para construir una imagen completa del comportamiento de la red en tiempo real.
Los protocolos más extendidos para recopilar estos datos son SNMP v3 para estado de dispositivos, ICMP para disponibilidad básica y la telemetría streaming para entornos de alta densidad. La clave no es acumular datos, sino convertirlos en alertas accionables: una alerta sobre utilización sostenida al 85% en un enlace WAN es útil; recibir 200 notificaciones de falsos positivos por hora no lo es. Una solución de monitoreo bien configurada reduce el tiempo medio de detección (MTTD) y acelera el troubleshooting al correlacionar eventos de distintas capas.
Operación y mantenimiento: actualizaciones, auditorías y gestión de cambios
La operación continua de una red empresarial requiere un calendario estructurado de mantenimiento preventivo: actualizaciones de firmware, revisión de reglas de firewall, rotación de credenciales y auditorías de configuración periódicas. Sin este ciclo, la red envejece de forma silenciosa: vulnerabilidades conocidas permanecen sin parchear y las configuraciones derivan del estado deseado.
La gestión de cambios de red formaliza cada modificación con un proceso de aprobación, ventana de mantenimiento y plan de rollback. Esto es especialmente crítico en entornos donde un cambio mal aplicado puede interrumpir servicios de producción. Complementar este proceso con pruebas de resiliencia periódicas —simulaciones de fallo de enlace, pruebas de conmutación de firewall— permite verificar que los mecanismos de recuperación funcionan antes de necesitarlos en una situación real. Para profundizar en la base física que sustenta todo esto, resulta útil revisar las mejores prácticas en mantenimiento de infraestructuras de red.

Arquitectura operativa: NOC, sistema de gestión y punto de control
Una red gestionada necesita un punto de control centralizado donde converjan datos, decisiones y responsables. Esta arquitectura operativa se articula en tres capas: el sistema de gestión de redes (NMS) que recopila y correlaciona datos, el NOC para empresas que procesa alertas y ejecuta respuestas, y la gobernanza que define SLAs, roles y procedimientos.
En Impulso Tecnológico, nuestro modelo operativo para servicios gestionados sigue un proceso estructurado que transforma datos brutos de red en acciones con trazabilidad completa:
- Recopilación centralizada: todos los dispositivos envían métricas, logs y telemetría al sistema de gestión mediante SNMP, syslog y agentes específicos del fabricante.
- Correlación y priorización: el NMS agrupa eventos relacionados, suprime ruido y genera alertas priorizadas por impacto en el negocio.
- Detección y clasificación: el equipo NOC valida la alerta, determina si es un incidente real y lo clasifica por severidad y área afectada.
- Escalado con responsables definidos: cada tipo de incidente tiene un árbol de escalado con tiempos máximos de respuesta y técnicos asignados.
- Resolución y documentación: la acción correctiva se aplica con registro completo: causa raíz, solución aplicada y tiempo de resolución.
- Revisión y mejora continua: los incidentes recurrentes alimentan el ciclo de mantenimiento preventivo para eliminar la causa raíz de forma definitiva.
Este modelo permite pasar de una gestión reactiva —donde el equipo IT responde cuando los usuarios reportan problemas— a una operación proactiva donde los fallos se detectan y resuelven antes de impactar la producción.
NOC y procesos: de la alerta al ticket con tiempos y responsables
Un NOC para empresas no requiere necesariamente un equipo interno dedicado; puede ser una función externalizada a un MSP con procesos bien definidos. Lo que sí es imprescindible es que el flujo de trabajo esté formalizado: cada alerta debe generar un ticket con timestamp, severidad, dispositivo afectado y técnico responsable asignado automáticamente.
Los tiempos de respuesta deben estar contractualmente definidos por nivel de severidad: un fallo de enlace WAN principal no puede tener el mismo SLA que una alerta de utilización elevada en un puerto secundario. En la práctica, un NOC eficaz distingue entre tiempo de detección (MTTD), tiempo de respuesta inicial y tiempo de resolución (MTTR), y reporta estas métricas periódicamente para demostrar el valor del servicio y detectar patrones de incidencias recurrentes que requieren atención preventiva.
Sistema de gestión de redes: inventario, configuración y control de cambios
El sistema de gestión de redes (NMS) es el registro de autoridad de la infraestructura: qué dispositivos existen, cuál es su configuración actual, cuál debería ser su estado deseado y qué cambios se han aplicado y cuándo. Sin este inventario actualizado, cualquier auditoría o respuesta a incidentes parte de cero.
Un NMS maduro integra descubrimiento automático de dispositivos, comparación de configuraciones actuales contra líneas base aprobadas, y alertas cuando se detectan desviaciones no autorizadas. Para entornos con equipos Cisco y Aruba —como los que gestiona Impulso Tecnológico—, las plataformas de gestión centralizada de cada fabricante ofrecen estas capacidades de forma nativa, y pueden complementarse con soluciones de terceros para entornos heterogéneos. El control de cambios dentro del NMS garantiza que cada modificación quede registrada con el responsable, la justificación y la posibilidad de revertir a la configuración anterior si algo falla.
Gobernanza empresarial: SLAs, entregables y políticas de operación
La gobernanza de la gestión de redes IT traduce los procesos técnicos en compromisos medibles para el negocio. Un SLA bien redactado especifica disponibilidad objetivo (por ejemplo, 99,5% mensual para la red LAN principal), tiempos de respuesta por severidad, ventanas de mantenimiento programado y exclusiones justificadas.
Más allá del SLA, la gobernanza define roles con claridad: quién aprueba cambios, quién es el interlocutor técnico del cliente, quién valida que los entregables mensuales —informe de incidencias, estado de actualizaciones, métricas de rendimiento— se han cumplido. En Impulso Tecnológico, nuestros contratos mensuales de servicio gestionado incluyen estos entregables de forma explícita, lo que permite al cliente tener visibilidad real del estado de su red sin necesidad de un equipo IT interno dedicado. Las políticas de operación completan el marco: qué está permitido cambiar sin aprobación previa, qué requiere ventana de mantenimiento y qué debe escalar a nivel directivo.
Cómo decidir herramientas o un servicio gestionado de gestión de redes IT
La decisión entre gestionar la red con herramientas propias o externalizar a un servicio gestionado de redes depende de cuatro variables: capacidad interna (equipo IT disponible y su nivel de especialización), complejidad de la infraestructura (número de sedes, dispositivos, entornos cloud y requisitos de seguridad), tolerancia al riesgo operativo y coste total de propiedad real —incluyendo licencias, formación y tiempo de gestión—.
Antes de evaluar opciones, conviene tener claros los criterios que no son negociables para tu operación:
- Escalabilidad: ¿la solución crece con tu infraestructura sin requerir una migración completa en 18 meses?
- Compatibilidad con tu stack actual: ¿soporta los fabricantes que ya tienes (Cisco, Aruba, Fortinet) o implica reemplazar equipos?
- Integración vía API: ¿puede conectarse con tu ITSM, tu SIEM o tus herramientas de automatización como n8n o Make.com?
- Gestión de alertas inteligente: ¿ofrece supresión de ruido, correlación de eventos y escalado por políticas configurables?
- Soporte a entornos virtualizados y cloud: ¿monitoriza VMs, contenedores y recursos en Azure o Microsoft 365?
- Modelo de licenciamiento: ¿el coste escala de forma predecible o hay sorpresas al añadir dispositivos o sedes?
- Capacidad de recuperación ante incidentes: ¿incluye integración con soluciones de backup y DR, o es solo monitoreo pasivo?
En Impulso Tecnológico ayudamos a las empresas a definir este alcance y a priorizar las capas de seguridad y continuidad según el riesgo real y el presupuesto disponible. Si la conclusión es externalizar, nuestro modelo de servicio gestionado incluye mantenimiento preventivo, monitorización activa, actualizaciones programadas y soporte técnico remoto y presencial con SLA definidos.
Comparativa práctica: herramientas vs servicio gestionado (pros y contras)
Gestionar la red con herramientas propias ofrece control total y personalización, pero exige un equipo IT con capacidad real de operar esas herramientas de forma continua. El coste visible —licencias de software— suele ser menor que el de un MSP, pero el coste oculto —horas de configuración, formación, actualizaciones y guardia ante incidentes— frecuentemente lo supera.
Un servicio gestionado de redes transfiere la operación a un equipo especializado con procesos ya maduros, SLAs contractuales y acceso a tecnologías de nivel enterprise que una PYME difícilmente justificaría adquirir por su cuenta. La contrapartida es menor control directo y dependencia del proveedor, que se mitiga con contratos flexibles y entregables transparentes. Para empresas con entre 50 y 500 usuarios, sin un equipo IT dedicado a redes, el MSP suele ofrecer mejor relación entre coste, cobertura y tiempo de respuesta que la alternativa de herramientas propias gestionadas de forma parcial. Puedes ver un ejemplo real de cómo se estructura este tipo de proyecto en el caso de éxito de implementación de red corporativa.
Checklist de evaluación: alertas, integración, licencias y entornos virtualizados
Antes de comprometerte con una herramienta o un proveedor, valida estos puntos con una prueba de concepto o una demo técnica real:
- ¿Las alertas se pueden configurar por política (no solo por umbral fijo) y se pueden suprimir durante ventanas de mantenimiento?
- ¿Los canales de notificación incluyen email, SMS y ticketing integrado con tu ITSM?
- ¿El inventario de dispositivos se actualiza automáticamente al añadir o retirar equipos?
- ¿La solución monitoriza entornos virtualizados (VMware, Hyper-V) y contenedores (Docker, Kubernetes)?
- ¿Dispone de API documentada para integrarse con herramientas de automatización o SIEM?
- ¿El modelo de licencias es por dispositivo, por usuario o por volumen de datos, y cómo escala al doblar el número de nodos?
- ¿Incluye informes de cumplimiento exportables para auditorías internas o requerimientos GDPR?
Este checklist evita la trampa más común: elegir una herramienta por su interfaz y descubrir después que no escala, no se integra o genera más ruido del que resuelve.
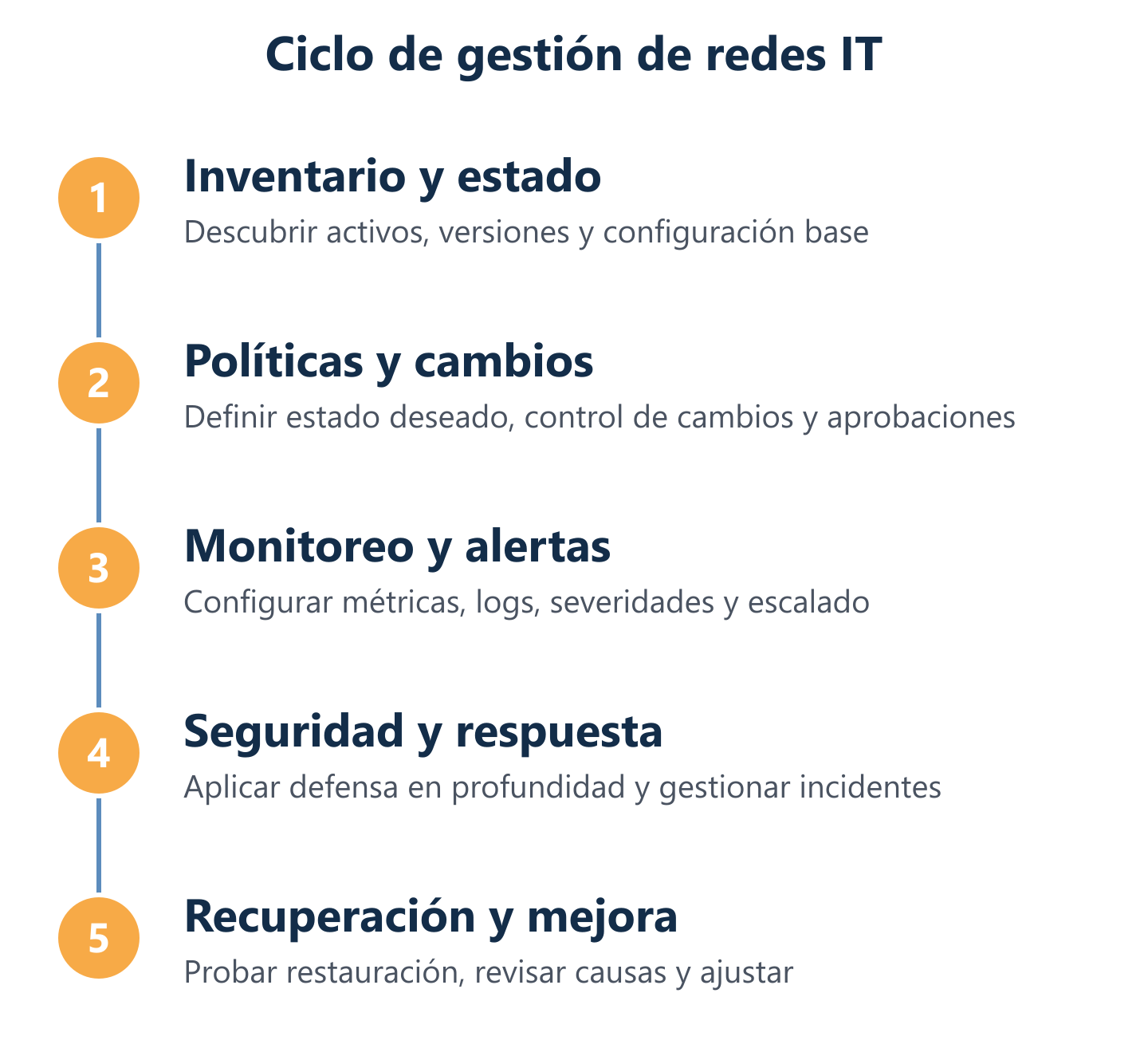
Implementación por fases: inventario, políticas, monitoreo, seguridad y recuperación
Un plan de implementación estructurado reduce el riesgo de proyectos que se eternizan o que arrancan con monitoreo pero nunca llegan a la seguridad y la continuidad. Una estructura realista en tres fases:
- Días 1-30 — Inventario y línea base: descubrimiento completo de dispositivos, documentación del estado actual, identificación de vulnerabilidades críticas y definición de políticas de configuración y acceso.
- Días 31-60 — Monitoreo activo y seguridad por capas: despliegue del NMS con alertas configuradas, implementación de las capas de seguridad prioritarias (firewall, segmentación, endpoint protection, VPN), y primer ciclo de actualizaciones de firmware.
- Días 61-90 — Continuidad y mejora continua: configuración y prueba de backups con Veeam u otra solución equivalente, simulacro de recuperación ante incidentes, revisión de SLAs con métricas reales y ajuste del plan de mantenimiento preventivo.
Cada fase debe terminar con entregables verificables: el inventario firmado, el
