
An IT consulting success story is a structured account of a defined business problem, the consulting approach used to address it, and the measurable outcomes achieved — covering cost, reliability, security, and scalability. Without all three elements, it is marketing, not evidence.
Most organisations evaluating an IT consulting partner face the same challenge: they encounter polished case studies full of positive language but short on specifics. The baseline problem is vague, the delivery method is glossed over, and the results lack attribution. That gap matters because a buyer cannot replicate success they cannot understand.
A credible IT consulting success story works differently. It starts with a precise description of the client's pain — operational disruptions, uncontrolled IT costs, security exposure, or failed scalability attempts — and then maps that pain to a structured delivery model. The outcome section quantifies what changed and explains why. At Impulso Tecnológico, with over 25 years of managed IT delivery across Spain, Portugal, and international clients, the stories that matter most are built on proactive monitoring, fast incident resolution, and predictable service performance. This guide gives you the framework to evaluate, build, and replicate that standard.
What makes an IT Consulting Success Story credible?
Before reading any case study, set your evaluation criteria. A credible IT consulting success story is not defined by the client's brand name or the consultant's reputation alone — it is defined by the rigour of its evidence. Three questions cut through the noise immediately: What was the measurable baseline before the engagement? What specific actions were taken and by whom? What changed, and how is that change attributed to the consulting work rather than external factors?
At Impulso Tecnológico, the foundation of every client engagement is built on proactive monitoring and clear communication — two factors that make the "before/after" narrative possible in the first place. With over 476 active clients and more than 4,000 IT tickets resolved annually, the service performance data exists to support that narrative. A high client satisfaction ratio, consistent SLA delivery, and structured incident handling are not soft claims; they are the operational signals that underpin any honest success story.
| Credibility Criterion | Weak Case Study | Strong Case Study |
|---|---|---|
| Baseline definition | "The client had IT challenges" | Specific downtime frequency, cost per incident, or compliance gap documented |
| Scope clarity | "We improved their infrastructure" | Named systems, number of sites, users, and integrations in scope |
| Delivery attribution | "Our team worked closely with the client" | Phased delivery model with milestones, governance checkpoints, and stakeholder sign-off |
| Outcome measurement | "Results exceeded expectations" | Quantified metrics: cost reduction, uptime improvement, ticket volume change, or risk score delta |
| Lessons learned | Absent or generic | Honest reflection on constraints, trade-offs, and what would be done differently |
Evidence checklist: baseline, scope, and success definition
Every credible IT consulting success story begins with a documented baseline — the "before" state that makes the outcome meaningful. Without it, any claimed improvement is unverifiable. When reviewing a case study, check for three baseline elements: the specific problem (not a category of problem), the operational context (number of users, sites, systems affected), and the agreed definition of success before work began.
Scope is equally important. A story that covers a single-site network upgrade is not comparable to a multi-country managed services rollout. Constraints matter too: budget ceilings, legacy system dependencies, regulatory requirements, and migration windows all shape what success realistically looks like. If a case study omits these, the results cannot be trusted or replicated.
Attribution and causality: what changed and why it worked
Attribution is the hardest part of any IT case study to get right — and the most commonly skipped. A result only becomes evidence when you can explain the causal chain: what was done, in what sequence, and why that specific action produced the observed change. Discovery workshops, infrastructure assessments, phased implementation plans, and governance checkpoints are not bureaucratic overhead; they are the mechanisms that make attribution possible.
When evaluating a success story, look for a delivery logic that connects problem to solution to outcome. For example: a security audit revealed unpatched endpoints across 12 sites → a Sophos endpoint protection rollout was completed in six weeks → incident frequency dropped by a documented amount over the following quarter. That chain is attributable. "We improved security" is not. The IT service governance model behind the engagement is what makes the difference.
Quality signals: governance, reporting cadence, and stakeholder alignment
Governance is what separates a one-off project from a repeatable consulting model. Strong IT consulting success stories include evidence of structured reporting: regular service reviews, SLA performance data, escalation paths, and stakeholder sign-off at key milestones. These signals tell you that outcomes were tracked intentionally, not discovered retrospectively.
Reporting cadence matters for buyers assessing a potential partner. Monthly service reviews, quarterly business reviews, and documented change management records indicate that the consulting team was accountable throughout — not just at project close. Stakeholder alignment is the third signal: if the case study shows that both IT and business leadership were engaged at decision points, the outcomes are far more likely to reflect genuine business value rather than technical metrics that no one in the boardroom cares about. Look for both in any IT managed services case study you evaluate.

The challenge: how the client's pain was defined
The strongest IT consulting case studies translate technical symptoms into business-language problem statements. A server that crashes is not the problem — unplanned downtime that costs the business a calculable amount per hour, or a compliance failure that risks regulatory action, is the problem. That translation is the first job of a consulting engagement, and how well it is done predicts how useful the eventual success story will be.
At Impulso Tecnológico, the managed services and MSP governance model functions as a structured "pain-to-plan" bridge. Preventive maintenance, continuous system monitoring, automated updates, backup and disaster recovery, and clear incident handling protocols are not reactive fixes — they are the operational infrastructure that converts vague discomfort into a documented, addressable problem statement. The process follows a consistent pattern:
- Symptom capture: Gather incident logs, user complaints, and operational data to establish what is visibly wrong.
- Business impact translation: Convert technical symptoms into cost, downtime, security risk, or scalability constraints that business stakeholders recognise.
- Root cause identification: Distinguish between surface-level issues and underlying architectural or process failures driving them.
- Priority ranking: Order problems by operational exposure and business continuity impact, not by technical complexity.
- Baseline documentation: Lock in the "before" state with measurable indicators so that post-engagement outcomes have a reference point.
This structured approach to problem definition is what makes cloud migration success metrics and security compliance outcomes reportable rather than anecdotal.
Business pain mapping: cost, downtime, security, scalability
Pain mapping is the process of connecting IT symptoms to the four business dimensions that boards and finance teams actually measure: cost, downtime, security exposure, and scalability constraints. Each dimension has its own set of indicators. Cost pain shows up as unpredictable IT spend, reactive break-fix billing, or duplicated vendor contracts. Downtime pain is measured in incident frequency, mean time to recovery, and the revenue or productivity lost per hour of outage. Security pain is quantified through audit findings, unpatched vulnerability counts, or compliance gaps. Scalability pain appears when infrastructure cannot support new headcount, new locations, or new workloads without disproportionate investment. Defining pain across all four dimensions — rather than just the one that triggered the engagement — gives the consulting team a complete picture and gives the eventual success story its full business context.
Scope and constraints: systems, locations, integrations, and dependencies
Scope definition is where many IT consulting engagements lose credibility before they begin. A scope statement must specify which systems are included (and which are not), how many physical or virtual locations are covered, how many end users are affected, and which third-party integrations or legacy dependencies exist. Equally important is what is explicitly out of scope — because undocumented assumptions about scope are the primary driver of cost overruns and missed outcomes.
For organisations with multi-site operations or international footprints, scope complexity increases significantly. Impulso Tecnológico's experience supporting clients across Spain, Portugal, and remote international locations means scope conversations routinely include questions about on-site versus remote support boundaries, language requirements, and time-zone-sensitive SLA windows. Getting these boundaries documented before delivery begins is not a formality — it is the condition under which a success story becomes replicable.
Risk framing: operational exposure and continuity requirements
Risk framing answers the question that scope definition leaves open: what happens if this engagement is delayed, descoped, or fails? Operational exposure includes the probability and impact of a security breach, a prolonged outage, or a compliance violation during the transition period. Continuity requirements define the minimum acceptable service level during implementation — for example, which systems cannot be taken offline, which data must remain accessible, and which regulatory deadlines are fixed.
For sectors such as healthcare, logistics, and financial services, these constraints are non-negotiable and must be documented before any migration window or infrastructure change is approved. A credible IT consulting success story will show that risk framing was completed upfront, not discovered mid-delivery. Technologies such as Veeam for backup and disaster recovery and Fortinet for network security are deployed precisely to maintain continuity while changes are implemented — reducing operational exposure without halting business operations.
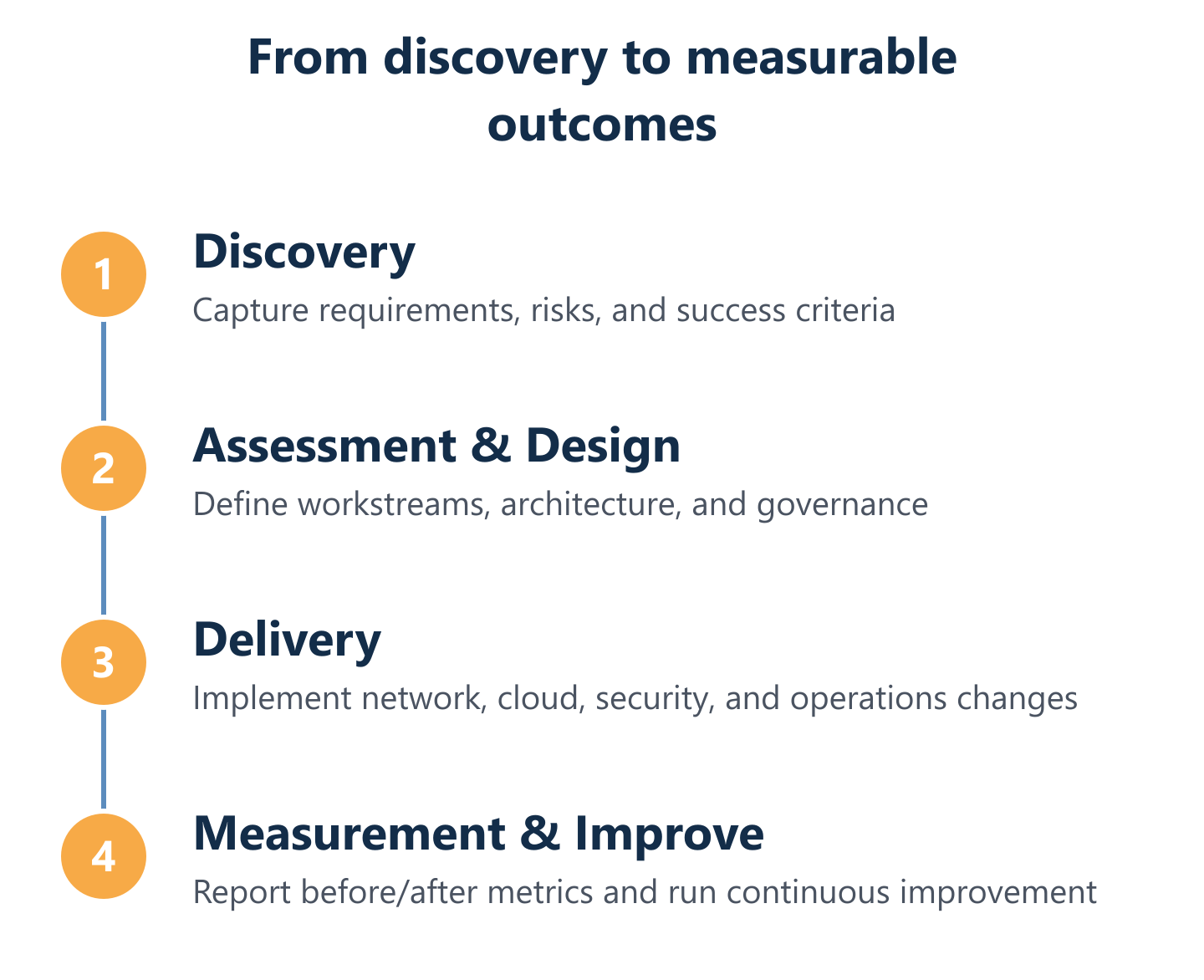
The approach and delivery: from discovery to measurable results
A consulting engagement that cannot describe its own delivery model cannot produce a credible success story. The approach section of any IT case study should answer four questions: How was the problem validated? How was the solution designed? How was delivery managed? And how were outcomes tracked after go-live?
At Impulso Tecnológico, consulting and managed delivery are combined into a single continuous model — which means improvements do not stop at implementation. The same team that designs the solution monitors its performance, manages incidents, and reports on outcomes over time. This is a structural advantage over project-only consulting firms that hand off and disengage. The delivery stack that supports this model includes:
- Cloud operations: Microsoft 365 and Azure environments, covering identity management, collaboration, licensing, and backup — with migration and ongoing management handled by the same team.
- Security and continuity: Sophos endpoint protection, Fortinet firewalls and network security, and Veeam backup and disaster recovery — deployed as an integrated layer, not isolated point solutions.
- Networking and infrastructure: Cisco and Aruba network design and deployment, structured cabling, and Fortinet-based segmentation for multi-site environments.
- Automation and integration: Workflow automation using Odoo, n8n, and Make.com to reduce manual overhead and embed AI-enabled productivity improvements into daily operations.
- Monitoring and managed services: Proactive system monitoring, preventive maintenance, and SLA-backed support — the operational layer that sustains every other workstream.
This breadth of capability means that cloud migration success metrics, security and compliance outcomes, and operational efficiency gains can all be measured within a single engagement rather than across disconnected vendor relationships. For more detail on how these services are structured, see our IT consulting and digital transformation overview.
Engagement mechanics: discovery, planning, execution, and governance
A repeatable engagement model is the backbone of any IT consulting success story worth replicating. The four-phase structure — discovery, planning, execution, and governance — is not theoretical; it is the operational sequence that makes attribution possible. Discovery validates the problem through infrastructure audits, stakeholder interviews, and data collection. Planning converts findings into a prioritised roadmap with defined milestones, resource requirements, and risk mitigations. Execution delivers changes in controlled phases, with change management records and rollback procedures in place. Governance closes the loop: regular service reviews, SLA performance reporting, and continuous improvement cycles ensure that the engagement does not end at go-live. Each phase produces documented outputs that become the evidence base for the eventual success story — and the reference point for the next engagement.
Delivery workstreams: systems, cloud, security, and operations
Delivery workstreams are the parallel tracks through which consulting recommendations become operational reality. In a typical IT consulting engagement, four workstreams run concurrently: systems and infrastructure (hardware refresh, structured cabling, server and storage), cloud (Microsoft 365 and Azure migration, identity, licensing), security (endpoint protection, firewall, backup, disaster recovery, GDPR compliance), and operations (monitoring, helpdesk, SLA management, preventive maintenance). Each workstream has its own milestones, dependencies, and success metrics. The most common failure mode is treating these as sequential rather than parallel — which extends timelines and creates gaps in coverage. Mapping solutions to workstreams from the outset, as part of the planning phase, is what allows a consulting team to report on IT consulting ROI by workstream rather than as a single aggregate figure. For a detailed view of how these workstreams are structured in practice, the IT services and integrated solutions page provides further context.
Outcome measurement: ROI framing for cost, reliability, and risk reduction
Outcome measurement is where the success story either earns its credibility or loses it. A before/after report that relies on SLA-aligned service data, incident volume comparisons, and documented cost changes is far more persuasive than a narrative summary. The ROI framework for IT consulting typically covers three dimensions: cost (monthly spend predictability, reduction in reactive break-fix costs, licence consolidation savings), reliability (uptime improvement, mean time to resolution, reduction in repeat incidents), and risk reduction (security audit findings closed, compliance gaps addressed, backup recovery tests passed). Each dimension should have a baseline figure, a post-engagement figure, and an attribution note explaining what specifically drove the change. Lessons learned — what constraints were encountered, what would be done differently — add the final layer of credibility that separates a genuine success story from a promotional summary.
If you can articulate the baseline, explain the delivery approach, and attribute the measurable change, you have the foundation to replicate success rather than simply celebrate it. The organisations that get the most from IT consulting are those that treat the success story not as a retrospective marketing exercise but as a live governance document — one that informs the next engagement from day one. Whether you are evaluating a potential partner or building the case for your own IT transformation, the evidence standards in this guide apply equally. Impulso Tecnológico's computer consulting services and IT consulting across Spain and Portugal are built on exactly this model — start with the right questions, and the results follow.
