
A corporate network implementation success case documents the full lifecycle of a network deployment—from identifying business risk and designing the architecture, through phased delivery and security validation, to quantified operational outcomes. It gives stakeholders a verified record of what changed, how it was governed, and what improved.
Most corporate networks fail not at the technical level but at the governance and measurement level. Organisations invest in hardware and connectivity, yet lack a structured narrative that connects infrastructure decisions to business results. Without that narrative, IT teams struggle to justify further investment, and business leaders cannot assess whether the project delivered value.
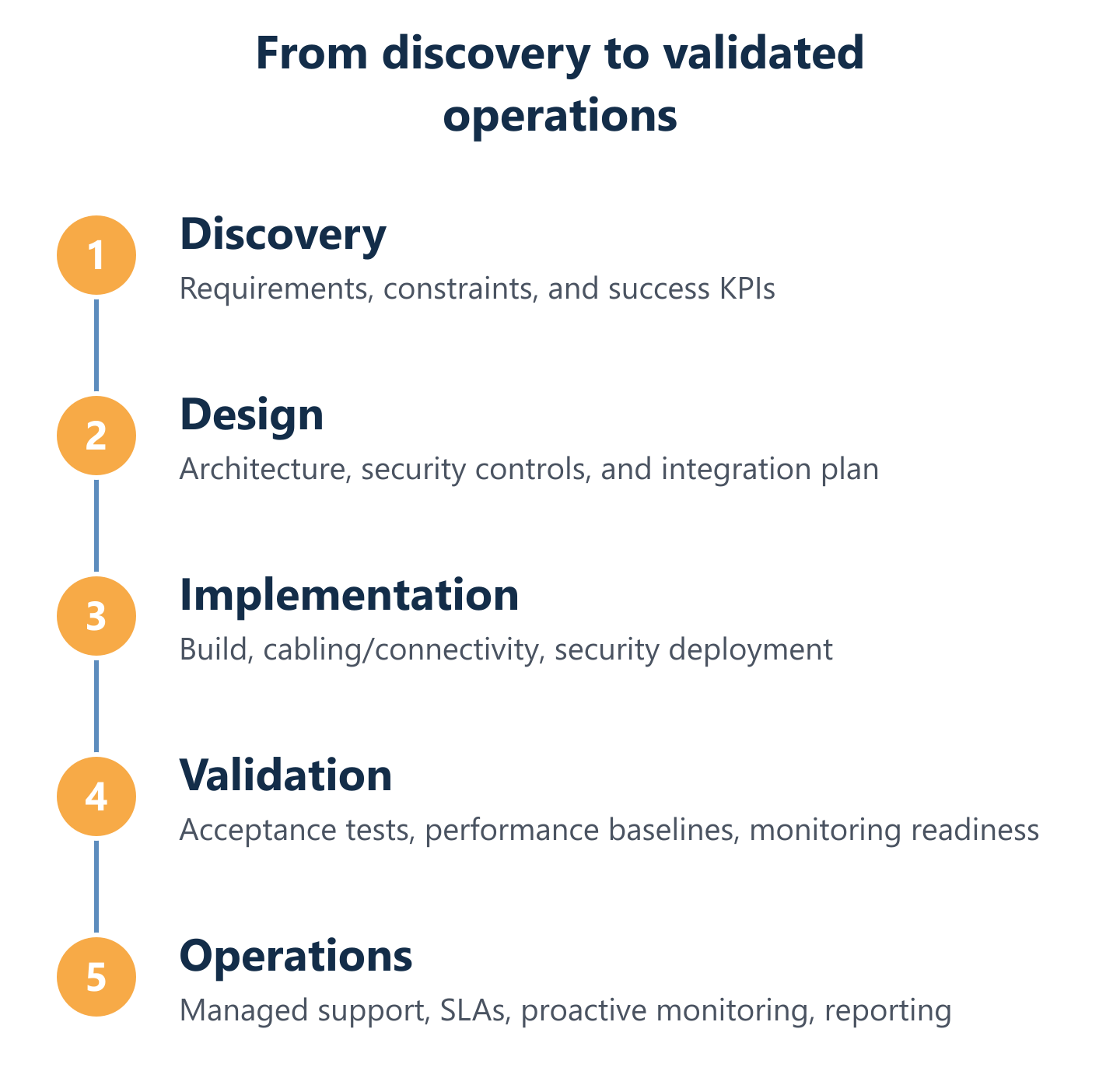
The approach that consistently works treats implementation as a lifecycle with defined phases: discovery and scoping, design and vendor selection, phased rollout, security validation, and operational handover with SLA-backed monitoring. Each phase produces documented evidence—test results, performance baselines, stakeholder sign-offs—that collectively form the success case. Impulso Tecnológico has applied this model across clients in Spain, Portugal, and internationally, combining multidisciplinary delivery with proactive managed operations to ensure that the network remains secure, measurable, and maintainable long after go-live.
The Corporate Network Challenge: what was broken and why it mattered
Before any architecture decision is made, the most important question is: what is the actual business cost of the current network's limitations? Organisations that skip this step tend to under-scope their projects, miss compliance requirements, and struggle to demonstrate ROI once delivery is complete.
In practice, the pain points that trigger a corporate network implementation project fall into three categories: reliability failures that disrupt operations, security gaps that expose the organisation to regulatory and financial risk, and structural rigidity that prevents growth. Each of these translates directly into measurable business exposure—lost productivity, potential GDPR penalties, or the inability to onboard new sites or users at speed.
Impulso Tecnológico approaches each engagement by mapping these symptoms to their business consequences before any design work begins. This framing—connecting infrastructure problems to operational and compliance risk—is what allows technical teams and business stakeholders to agree on scope, priority, and success criteria from day one.
| Network Problem | Business Risk | Typical Impact | Priority Level |
|---|---|---|---|
| Unplanned downtime / single points of failure | Operational disruption, SLA breaches | Revenue loss, staff productivity drop | Critical |
| Outdated firewall or unmanaged endpoints | Cybersecurity exposure, GDPR non-compliance | Data breach risk, regulatory fines | Critical |
| Legacy flat topology, no segmentation | Lateral threat movement, poor access control | Breach containment failure | High |
| No centralised monitoring or asset inventory | Blind spots in operations, slow incident response | Extended mean time to resolution (MTTR) | High |
| Manual change management, no documentation | Configuration drift, audit failures | Compliance gaps, re-work costs | Medium |
Corporate drivers: resilience, compliance, and growth readiness
Network symptoms rarely stay in the IT department. A recurring outage becomes a board-level conversation when it delays customer deliveries or disrupts financial reporting. An unpatched firewall becomes a legal liability the moment a data breach triggers a GDPR investigation. Growth ambitions—new offices, hybrid working, cloud adoption—stall when the underlying network cannot scale without costly re-architecture.
Translating these symptoms into business language is the first step in building a compelling corporate network implementation success case. Stakeholders need to see three things: the operational resilience risk (what breaks and how often), the compliance exposure (which regulations apply and where the gaps are), and the growth constraint (what the business cannot do today because of network limitations). Framing the project around these three drivers ensures that investment decisions are made on business merit, not technical preference.
Common failure points: legacy topology, poor visibility, and slow change
The most common reason corporate network projects fail to deliver measurable results is that success criteria were never defined before implementation began. Without a baseline—documented uptime figures, average provisioning times, incident volumes, latency measurements—there is no way to prove that anything improved.
Legacy flat topologies are a persistent problem: networks built without segmentation allow a single compromised device to reach every system on the estate. Poor visibility compounds this—organisations without centralised monitoring tools cannot detect anomalies, track asset changes, or respond to incidents before they escalate. Slow change management, driven by undocumented configurations and manual processes, creates configuration drift over time and makes audits painful. Defining success criteria early—reliability targets, security posture benchmarks, scalability requirements, and change control constraints—turns these failure points into measurable objectives that the implementation must address.
Stakeholder alignment: scope, acceptance criteria, and bilingual communication
Corporate network projects involve more stakeholders than most IT teams anticipate. Beyond the network engineers, decisions touch facilities managers (cabling routes, rack space, power), security officers (policy enforcement, access control), finance (budget approval, cost tracking), and business unit owners (service continuity expectations). Each group has different priorities and a different definition of "done."
Mapping these stakeholders early—and assigning clear acceptance criteria to each phase—prevents the most common project governance failure: a technically complete deployment that business stakeholders refuse to sign off because their requirements were never formally captured. In the Iberian market, where relationship-driven decision-making and milestone expectations can differ from Northern European norms, bilingual communication in Spanish and English is not a courtesy—it is a delivery requirement. Impulso Tecnológico builds milestone definitions and acceptance documentation into every engagement to ensure that all parties share a common understanding of scope and completion criteria throughout the enterprise network rollout.

Implementation Blueprint: architecture, services, and integration approach
A corporate network implementation succeeds when it is treated as an integrated delivery lifecycle, not a sequence of independent technical tasks. The architecture must account for physical foundations, logical design, security controls, and operational handover simultaneously—because decisions made in one layer directly constrain what is possible in the others.
Impulso Tecnológico structures delivery around a repeatable pattern that has been refined across engagements in Spain, Portugal, and internationally. The pattern ensures that each phase produces documented outputs—site surveys, design specifications, test results, runbooks—that serve both the immediate project and the long-term managed operations model. Multi-vendor network management is handled through certified partnerships with Cisco, Aruba, Fortinet, and Sophos, allowing the team to select the right technology for each layer without being constrained by a single vendor's portfolio.
- Discovery and site assessment: Document existing infrastructure, identify constraints, and establish performance baselines.
- Architecture design: Define topology, segmentation model, addressing scheme, and vendor selection aligned to client requirements.
- Physical foundations: Structured cabling, fibre installation, rack and communications room build-out.
- Network services deployment: Routing, switching, wireless, DHCP/DNS, and identity integration.
- Security controls integration: Firewall policy, endpoint protection, access control, and backup configuration.
- Validation and acceptance testing: Performance benchmarking, failover testing, and stakeholder sign-off.
- Operational handover: SLA definition, monitoring dashboard activation, documentation handover, and managed services onboarding.
Network foundations: cabling, fibre, and connectivity readiness
Every performance and reliability target defined in the scoping phase ultimately depends on the physical layer. Structured cabling that does not meet category standards, fibre runs with insufficient headroom, or communications rooms without proper power and cooling will undermine even the most sophisticated logical design.
Impulso Tecnológico delivers complete structured cabling services covering data networks, voice communications, and fibre optic installations, treating the physical layer as a first-class deliverable rather than a pre-condition. Site readiness assessments identify cable routes, rack capacity, and power requirements before procurement begins, preventing the mid-project surprises—insufficient conduit space, inadequate earthing, missing fibre runs—that delay go-live dates and inflate costs. Certified installations also provide the audit trail that compliance and facilities teams require, particularly in regulated sectors such as healthcare, education, and financial services.
Security-by-design: vendor controls and unified protection for IT and premises
Network security cannot be retrofitted after go-live without significant re-work. Designing security controls into the architecture from the outset—network segmentation, firewall policy, endpoint protection, and access management—is both more effective and more cost-efficient than layering security onto an existing flat topology.
Impulso Tecnológico implements security using a multi-vendor approach anchored on Fortinet for perimeter and network security and Sophos for endpoint and threat detection, with Veeam providing backup and disaster recovery capabilities where required. This combination addresses the most common corporate risk vectors: lateral movement through unsegmented networks, unprotected endpoints, and data loss from ransomware or hardware failure. For organisations requiring a unified approach to premises protection, the security design extends to physical access control and video surveillance using Verkada, creating a single managed security posture that covers both IT infrastructure and physical premises—a capability that is particularly relevant for multi-site corporate environments. Network security validation is built into the acceptance testing phase, not treated as an afterthought.
Operational integration: managed services, SLAs, documentation, and proactive monitoring
A network that is well-designed and correctly installed will still degrade over time without structured operational management. Configuration drift, unpatched firmware, undocumented changes, and reactive-only support are the most common causes of performance decline in the months following a successful go-live.
Impulso Tecnológico's managed network operations model addresses this through SLA-backed support contracts, centralised monitoring, and proactive incident detection—identifying issues before they affect users rather than waiting for tickets to arrive. Every engagement includes a documentation handover covering network diagrams, configuration baselines, change logs, and runbooks, ensuring that the operations team has the information needed to manage the environment confidently. This approach supports the broader goal of network infrastructure maintenance as a continuous discipline rather than a reactive cost centre. Monthly reporting against agreed network performance KPIs gives both IT and business stakeholders a consistent view of service quality and a clear basis for capacity planning.
Validation and measurable outcomes: proving success to the business
The difference between a completed project and a proven success case is evidence. Stakeholders—particularly those outside IT—need to see quantified outcomes, not just a list of technologies deployed. Building a validation framework into the project from the outset ensures that the evidence exists when it is needed.
Impulso Tecnológico structures validation around three categories of proof: performance outcomes (measured against the baselines established during discovery), security outcomes (verified through acceptance testing and policy audits), and operational outcomes (tracked through managed services reporting). Across the client base, the team resolves over 4,000 IT support tickets annually and maintains high client satisfaction scores, with 476 active clients supported in Spanish and English—figures that reflect the operational discipline applied to every engagement.
- Performance baseline comparison: Document latency, throughput, and uptime before and after implementation to show measurable improvement.
- Provisioning speed reduction: Track how long it takes to onboard a new device, user, or site under the new architecture versus the legacy environment.
- Incident volume and MTTR trends: Compare ticket volumes and resolution times in the first 90 days post-go-live against the pre-project baseline.
- Security posture validation: Confirm firewall policy compliance, endpoint protection coverage, and backup recovery test results as formal acceptance criteria.
- Stakeholder sign-off documentation: Capture formal acceptance from IT, security, facilities, and business owners at each phase gate—not just at project close.
- Ongoing KPI reporting: Establish monthly reporting cycles covering uptime, incident trends, and capacity utilisation to demonstrate sustained value beyond go-live.
What to measure: provisioning speed, latency, downtime, and ticket reduction
Choosing the right metrics before implementation begins is as important as the technical design itself. The most useful network performance KPIs for a corporate success case are those that connect directly to business operations: provisioning time (how quickly a new user or site can be brought online), end-to-end latency on business-critical applications, unplanned downtime frequency and duration, and support ticket volume by category.
Each metric requires a documented baseline—measured during the discovery phase—so that post-implementation figures are directly comparable. Failover behaviour deserves specific attention: testing whether redundant links and backup systems activate within defined thresholds is not optional for business-critical environments. Trend data over the first three to six months post-go-live is more persuasive than a single point-in-time measurement, as it demonstrates that improvements are sustained rather than coincidental.
How to validate: acceptance testing, monitoring dashboards, and operational readiness
Acceptance testing should be structured around the success criteria defined at project initiation, not improvised at go-live. A formal test plan covers connectivity verification across all network segments, application performance under realistic load, failover and recovery testing for redundant paths, and security policy validation—confirming that firewall rules, access controls, and endpoint protection are functioning as designed.
Monitoring dashboards serve a dual purpose: they provide the operations team with real-time visibility for day-to-day management, and they generate the historical data needed to build the success narrative for stakeholders. Operational readiness checks—confirming that runbooks are complete, support contacts are documented, and escalation paths are agreed—are the final gate before handover. For organisations working with Impulso Tecnológico's IT network management services, this handover feeds directly into the ongoing managed operations model, ensuring continuity between project delivery and long-term support.
How to report: CFO-friendly impact and stakeholder-ready success narrative
Technical outcomes need translation before they reach the boardroom. A CFO does not need to understand BGP routing; they need to understand that the new network reduced unplanned downtime by a specific number of hours per quarter, that provisioning a new site now takes days rather than weeks, and that the consolidated managed services model replaced several fragmented vendor contracts with a single predictable monthly cost.
The most effective corporate network implementation success case narratives follow a consistent structure: the business problem and its cost, the solution approach and governance model, the validated outcomes with supporting data, and the ongoing operational model that protects the investment. Framing cost impact in terms of reduced operational expenditure, avoided incident costs, and improved staff productivity gives finance stakeholders the language they need to support continued IT investment. This is the document that turns a completed project into a strategic asset.
A corporate network implementation success case is most valuable when it is built as a living document throughout the project—not assembled retrospectively from memory. Every phase gate, test result, and stakeholder sign-off contributes to a record that demonstrates not just what was delivered, but how it was governed and what it changed for the business. If you can show the full arc from corporate risk to verified outcomes, the success case becomes a decision tool for future investment, a reference for compliance audits, and a foundation for the ongoing managed operations that protect the network long after go-live. The organisations that do this consistently are the ones that treat network implementation as a business programme, not a technical task.
