
El mantenimiento informático proactivo es un modelo de gestión IT que detecta y resuelve riesgos tecnológicos antes de que provoquen fallos. A diferencia del enfoque reactivo —que actúa cuando el sistema ya ha fallado—, el proactivo combina monitorización continua, actualizaciones planificadas y copias de seguridad validadas para mantener la infraestructura estable y segura.
Muchas empresas siguen operando bajo el modelo de "llamar cuando algo se rompe". El problema es que ese modelo tiene un coste real: tiempo de inactividad no planificado, pérdidas de productividad, reparaciones urgentes más caras y, en el peor caso, brechas de seguridad que podrían haberse evitado. Cuando un servidor cae en mitad de la jornada laboral o un ransomware cifra los datos porque un parche crítico llevaba semanas pendiente, el daño ya está hecho.
El mantenimiento informático proactivo invierte esa lógica: se trabaja con un plan estructurado, con alertas configuradas, ventanas de mantenimiento programadas y métricas que permiten tomar decisiones antes de que un problema menor se convierta en una crisis. El resultado es una infraestructura más predecible, presupuestos IT más controlados y una operación que no depende de urgencias.
Qué es el mantenimiento informático proactivo y por qué evita el enfoque reactivo
El mantenimiento informático proactivo no es simplemente "hacer revisiones periódicas": es un modelo de gestión basado en datos, alertas y planes de acción que actúa antes de que los problemas impacten en la operación. Frente al modelo reactivo —donde el equipo IT solo interviene cuando el usuario reporta un fallo—, el proactivo establece líneas base de rendimiento, umbrales de alerta y protocolos de respuesta que reducen drásticamente el tiempo de inactividad no planificado.
En Impulso Tecnológico llevamos más de 25 años aplicando este enfoque con clientes de sectores como industria, logística y servicios profesionales. La diferencia práctica es clara: en lugar de gestionar tickets aislados, trabajamos con monitorización continua sobre servidores, endpoints y entornos cloud, apoyándonos en tecnologías como Sophos para protección de endpoint, Fortinet para seguridad perimetral y Veeam para copias de seguridad. Sobre Microsoft 365 y Azure, gestionamos identidades, licencias y copias de seguridad de forma planificada. Todo ello con SLA definidos y comunicación transparente, para que la continuidad operativa no dependa de reaccionar ante urgencias.
| Criterio | Mantenimiento reactivo | Mantenimiento proactivo |
|---|---|---|
| Momento de intervención | Tras el fallo | Antes del fallo |
| Coste por incidencia | Alto (urgencias, horas extra) | Bajo (acciones planificadas) |
| Previsibilidad presupuestaria | Baja (costes variables) | Alta (cuota mensual fija) |
| Tiempo de inactividad | No planificado, mayor impacto | Reducido y controlado |
| Gestión de seguridad | Reactiva (tras brecha o alerta) | Continua (parches y auditorías) |
| Documentación | Escasa o inexistente | Actualizada y auditada |
Definición práctica de mantenimiento informático proactivo
El mantenimiento informático proactivo es el conjunto de acciones planificadas y automatizadas que permiten detectar señales de riesgo en la infraestructura IT —servidores, equipos, redes, aplicaciones y entornos cloud— antes de que se conviertan en incidencias que paralicen el negocio. No se trata solo de instalar actualizaciones: implica conocer el estado real de cada activo, establecer umbrales de comportamiento normal y actuar cuando se detectan desviaciones. A diferencia del mantenimiento preventivo clásico —que opera en ciclos fijos independientemente del estado del sistema—, el proactivo prioriza según el riesgo real detectado en cada momento, lo que lo hace más eficiente y adaptado a entornos IT dinámicos.
Riesgos del enfoque reactivo en equipos, servidores y cloud
Operar en modo reactivo en entornos IT expone a la empresa a riesgos que van mucho más allá de un equipo lento. Un servidor sin parches críticos aplicados durante semanas es una superficie de ataque abierta. Un disco con señales de degradación que no se monitoriza puede fallar sin aviso, llevándose consigo datos sin copia de seguridad validada. En entornos cloud como Microsoft 365 o Azure, las configuraciones incorrectas o los accesos no revisados son vectores habituales de compromiso. Cada incidencia no planificada genera costes directos —horas de soporte urgente, hardware de sustitución— e indirectos: productividad perdida, plazos incumplidos y, en sectores regulados, posibles sanciones por incumplimiento del GDPR.
Cómo se traduce en continuidad operativa y seguridad
La continuidad operativa no es un objetivo abstracto: se mide en horas de disponibilidad, en la velocidad de recuperación ante un fallo y en la ausencia de sorpresas que paralicen la actividad. El mantenimiento informático proactivo la garantiza porque actúa sobre las causas antes de que se manifiesten los síntomas. Cuando la monitorización detecta un pico anómalo de temperatura en un servidor o un aumento inusual del tráfico de red, el equipo técnico puede intervenir dentro de una ventana planificada, sin afectar a los usuarios. En Impulso Tecnológico, para servidores críticos trabajamos con un objetivo de respuesta inferior a cuatro horas, lo que limita el impacto operativo incluso en los escenarios más exigentes. La seguridad se refuerza de forma continua, no puntual.

Qué incluye una estrategia proactiva IT: alcance y componentes
Una estrategia de mantenimiento proactivo IT no se improvisa: parte de un conocimiento preciso del entorno y se articula en fases con responsables, frecuencias y criterios de validación definidos. En Impulso Tecnológico, el punto de partida de cualquier proyecto es una auditoría tecnológica inicial que evalúa el estado real de la infraestructura, identifica riesgos prioritarios y genera un plan de acción estructurado. A partir de ahí, el servicio se despliega en capas que cubren desde la monitorización de servidores y endpoints hasta la gestión de ciberseguridad y los planes de recuperación ante desastres, con soporte remoto y presencial según las necesidades del cliente.
- Auditoría inicial: inventario completo de activos, versiones de software, configuraciones y riesgos identificados.
- Monitorización continua: supervisión de servidores, endpoints, redes y entornos cloud con alertas configuradas por umbrales.
- Gestión de parches y actualizaciones: aplicación planificada en ventanas de mantenimiento para minimizar el impacto en producción.
- Ciberseguridad gestionada: firewall, protección de endpoint, control de accesos y revisión periódica de políticas de seguridad.
- Copias de seguridad y recuperación: backups automatizados con pruebas de restauración validadas, no solo almacenamiento.
- Documentación técnica: registro actualizado de configuraciones, cambios y procedimientos para garantizar la continuidad.
- Reporting periódico: informes con métricas clave, incidencias gestionadas y recomendaciones de mejora para la toma de decisiones.
Monitorización y alertas: de la señal al ticket accionable
La monitorización de servidores y endpoints es el sistema nervioso de cualquier estrategia proactiva. Su valor no está en recoger datos, sino en convertir señales en acciones antes de que el problema sea visible para el usuario. Para ello, el primer paso es construir un inventario real y actualizado: qué equipos hay, qué versiones de sistema operativo y software ejecutan, qué configuraciones tienen y cuál es su comportamiento habitual. Sin esa línea base, cualquier alerta carece de contexto. A partir del inventario, se configuran umbrales —uso de CPU, espacio en disco, latencia de red, estado de servicios críticos— que generan tickets automáticos priorizados por severidad. En Impulso Tecnológico integramos esta capa de monitorización con nuestros procesos de soporte para que cada alerta relevante se traduzca en una acción concreta y documentada.
Parches, actualizaciones y auditorías: control de riesgos y estabilidad
La gestión de parches y actualizaciones es uno de los componentes con mayor impacto directo en la seguridad y estabilidad del entorno IT. Aplicar un parche crítico días después de su publicación reduce significativamente la ventana de exposición a vulnerabilidades conocidas. Sin embargo, hacerlo sin control puede introducir incompatibilidades que afecten a la producción. La clave está en el control de cambios: definir ventanas de mantenimiento preventivo IT fuera del horario crítico, probar las actualizaciones en entornos no productivos cuando sea posible y documentar cada cambio. Las auditorías periódicas —al menos trimestrales— permiten detectar configuraciones que han derivado del estándar, software no autorizado o licencias caducadas que representan riesgos tanto de seguridad como de cumplimiento normativo.
Backups, recuperación y documentación: evidencia para continuidad
Una copia de seguridad que nunca se ha probado no es una garantía: es una esperanza. Las copias de seguridad y recuperación ante desastres son el último eslabón de la continuidad de negocio, y su valor real solo se demuestra cuando se restaura con éxito. En una estrategia proactiva, los backups deben ser automatizados, con retención definida según la criticidad de los datos, y sometidos a pruebas de restauración periódicas documentadas. Herramientas como Veeam permiten verificar la integridad de las copias y simular recuperaciones sin afectar al entorno productivo. La documentación técnica completa este ciclo: sin un registro actualizado de configuraciones y procedimientos de recuperación, incluso un backup perfecto puede tardar horas en restaurarse correctamente. La documentación es evidencia operativa, no burocracia.
Cómo implementar y medir el éxito del mantenimiento informático proactivo
Implementar un modelo de mantenimiento proactivo de TI requiere más que instalar herramientas: exige un proceso estructurado que vaya del diagnóstico inicial a la mejora continua, con métricas que permitan demostrar el valor generado. La justificación ante dirección no puede basarse en "hemos evitado problemas" sin evidencia: necesita datos comparables mes a mes.
En Impulso Tecnológico trabajamos con acuerdos de SLA que establecen tiempos de respuesta objetivos, soporte multicanal —remoto y presencial— y un enfoque de previsibilidad presupuestaria que sustituye los costes variables por una cuota mensual controlada. Además, integramos consultoría continua para alinear la tecnología con los objetivos del negocio, identificar oportunidades de optimización y, cuando procede, incorporar automatizaciones con herramientas como n8n, Make.com u Odoo que reducen tareas manuales repetitivas.
- Señal de madurez baja: el equipo IT solo actúa cuando los usuarios reportan fallos y no hay registro de activos actualizado.
- Señal de madurez media: existen copias de seguridad automatizadas, pero no se prueban; los parches se aplican de forma irregular.
- Señal de madurez alta: monitorización activa, ventanas de mantenimiento planificadas, backups con restauración validada y reporting mensual con KPIs.
- Criterio para externalizar: si el equipo interno no puede cubrir la monitorización continua, la gestión de parches y la respuesta ante alertas con los recursos disponibles, la externalización parcial o total es la opción más eficiente.
- Resultado esperado: reducción de incidencias no planificadas, mayor disponibilidad de sistemas y presupuesto IT más predecible.
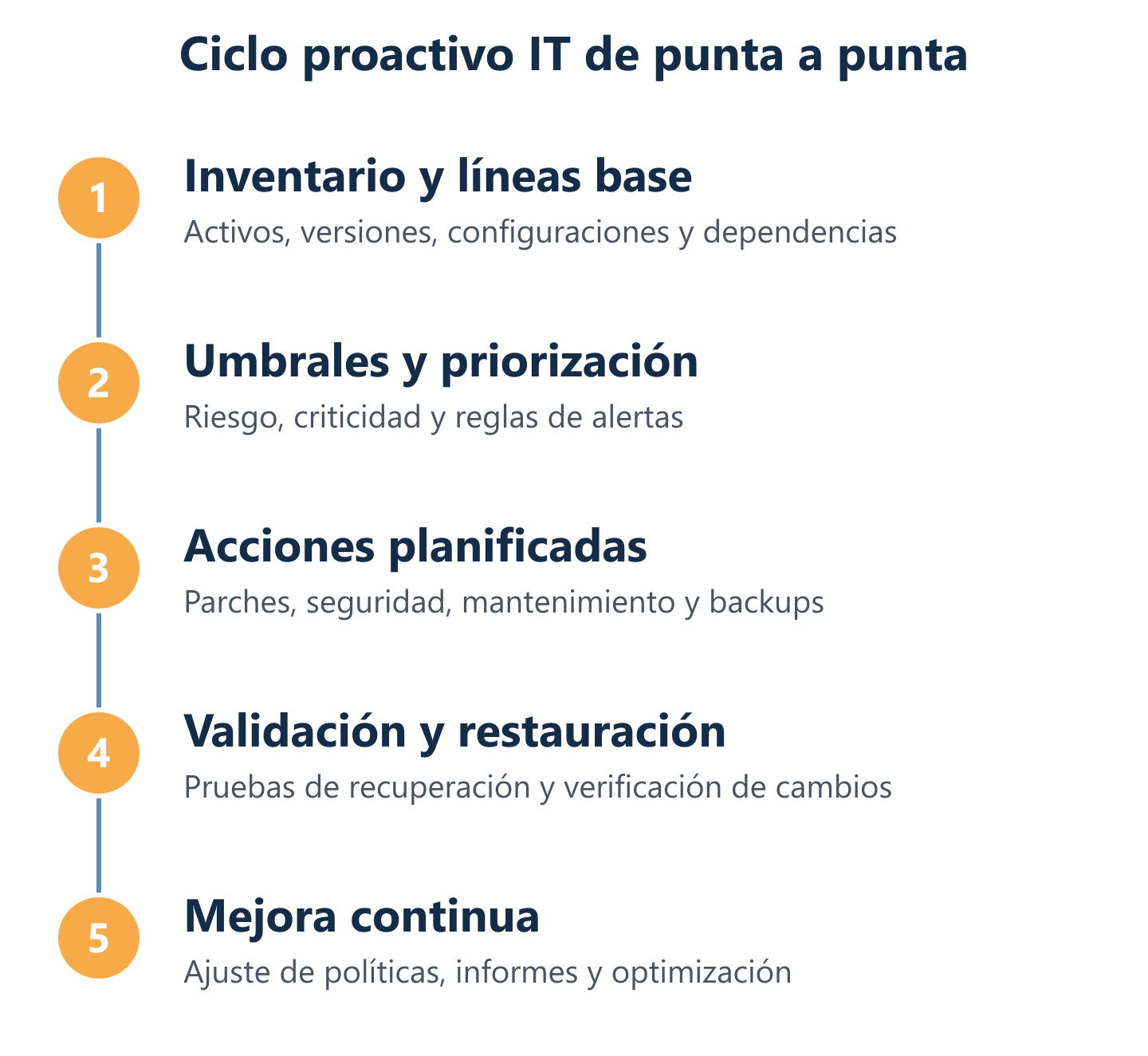
Flujo de implementación paso a paso: del inventario a la mejora continua
- Inventario y auditoría inicial: catalogar todos los activos IT (hardware, software, versiones, configuraciones) y evaluar el estado real frente a buenas prácticas.
- Definición de líneas base y umbrales: establecer el comportamiento normal de cada sistema y los límites que disparan alertas.
- Configuración de monitorización: desplegar agentes o herramientas de supervisión sobre servidores, endpoints y entornos cloud.
- Planificación de ventanas de mantenimiento: programar parches, actualizaciones y revisiones en horarios de bajo impacto para la operación.
- Ejecución y validación: aplicar acciones planificadas, documentar cambios y verificar que el sistema mantiene su estabilidad tras cada intervención.
- Reporting y revisión periódica: analizar métricas mensuales, identificar tendencias y ajustar el plan de acción para el siguiente ciclo.
Indicadores y reportes: qué medir para tomar decisiones
Los KPIs de un servicio de mantenimiento proactivo IT deben responder a una pregunta concreta: ¿está mejorando la estabilidad y seguridad del entorno? Los indicadores más útiles incluyen el número de incidencias no planificadas por mes —y su evolución comparada—, el porcentaje de disponibilidad de sistemas críticos, el tiempo medio de resolución de alertas, el nivel de cumplimiento del plan de parches (parches críticos aplicados en el plazo definido) y el resultado de las pruebas de restauración de backups. El reporting mensual no es un trámite administrativo: es la herramienta que permite a dirección tomar decisiones sobre inversión tecnológica con datos reales. En Impulso Tecnológico incluimos en nuestros informes tanto el estado del entorno como las recomendaciones de mejora priorizadas por impacto y urgencia.
Cuándo externalizar y cómo elegir un partner IT
La decisión de externalizar la gestión proactiva IT responde a una evaluación honesta de la capacidad interna. Si el equipo IT no puede dedicar tiempo a la monitorización continua, la gestión de parches y la respuesta ante alertas sin descuidar otros proyectos, la externalización no es una señal de debilidad: es una decisión estratégica. Al evaluar un partner, los criterios clave son: experiencia demostrable en entornos similares al tuyo, SLA con tiempos de respuesta definidos y verificables, flexibilidad contractual sin permanencias rígidas, capacidad de soporte tanto remoto como presencial, y transparencia en la comunicación —informes periódicos, no solo respuestas a incidencias—. También es relevante que el partner trabaje con fabricantes certificados como Sophos, Fortinet, Veeam o Microsoft, lo que garantiza acceso a soporte de nivel avanzado. Puedes consultar nuestra guía sobre cómo presupuestar el mantenimiento informático para entender qué factores influyen en el coste de este tipo de servicio.
El mantenimiento informático proactivo no es un gasto adicional: es la diferencia entre operar con control o depender de la suerte. Si tu empresa todavía resuelve problemas cuando ya han ocurrido, el primer paso es una auditoría tecnológica que identifique los riesgos reales y permita definir un plan priorizado. En Impulso Tecnológico acompañamos a empresas de todos los tamaños en ese proceso, desde el diagnóstico inicial hasta la gestión continua, con la flexibilidad y la cercanía que necesita cada proyecto. También puedes ampliar información en nuestro artículo sobre mantenimiento informático preventivo para empresas o, si ya tienes claro que necesitas soporte local, consultar nuestras páginas de mantenimiento informático en Alcalá de Henares y otras ubicaciones.
