
El mantenimiento correctivo IT es el conjunto de acciones técnicas que se ejecutan para restaurar el funcionamiento normal de un sistema, servicio o componente tras un fallo o degradación no planificada. Su objetivo es reducir el tiempo de inactividad y el impacto operativo al mínimo posible.
Cuando un servidor deja de responder, un switch de red pierde conectividad o un sistema operativo se corrompe, cada minuto sin servicio tiene un coste directo: operaciones detenidas, usuarios bloqueados y, en muchos casos, riesgo para los datos. La diferencia entre una empresa que resuelve ese incidente en minutos y otra que tarda horas no está en la suerte, sino en tener un proceso definido: quién detecta, quién actúa, con qué criterio se prioriza y cómo se verifica que el servicio ha vuelto a operar con normalidad.
Esta guía cubre exactamente eso: los disparadores que activan el correctivo, los tipos de intervención según urgencia e impacto, el flujo operativo de diagnóstico a cierre, y las métricas que permiten reducir la recurrencia. Tanto si gestionas tu IT internamente como si trabajas con un proveedor de servicios gestionados, contar con este marco marca la diferencia entre reaccionar y controlar.
Qué es el mantenimiento correctivo IT y por qué es crítico
El mantenimiento correctivo IT agrupa todas las intervenciones técnicas que se ejecutan después de que un componente, sistema o servicio ha fallado o ha comenzado a degradarse. A diferencia de otras disciplinas de mantenimiento, aquí no hay planificación previa: el punto de partida es siempre un síntoma real —una alerta, una queja de usuario o un corte de servicio— y el objetivo es devolver la operación a su estado funcional con el menor impacto posible en el negocio.
Este tipo de mantenimiento abarca tanto la capa de infraestructura física (servidores, almacenamiento, switches, routers, endpoints) como la capa lógica (sistemas operativos, aplicaciones, servicios de red, entornos cloud). Tratar ambas capas como un único dominio es esencial: un fallo de hardware puede desencadenar una corrupción de datos, y un error de software puede inutilizar un equipo perfectamente operativo.
En Impulso Tecnológico integramos el correctivo dentro del servicio gestionado: cada incidencia se recibe, se clasifica y se resuelve dentro del mismo flujo de soporte, sin que el cliente tenga que coordinar proveedores ni gestionar escalados. Con más de 25 años en el sector y más de 4.000 tickets IT resueltos anualmente, el equipo actúa con un proceso definido tanto en remoto como en presencial.
| Dimensión | Infraestructura física | Sistemas y software | Servicios cloud y red |
|---|---|---|---|
| Ejemplos de fallo | Disco duro averiado, fuente de alimentación, switch caído | OS corrupto, parche de emergencia, aplicación no arranca | Caída de VPN, servicio Microsoft 365 inaccesible, fallo de DNS |
| Impacto típico | Pérdida de datos, servidor fuera de servicio | Usuarios bloqueados, pérdida de productividad | Comunicaciones cortadas, acceso remoto interrumpido |
| Tipo de intervención | Sustitución de componente, restauración de backup | Reinstalación, rollback, aplicación de parche | Reconfiguración, failover, escalado al proveedor |
| Herramientas de apoyo | Veeam (backup/recovery), Fortinet (diagnóstico de red) | Sophos (endpoint), herramientas de diagnóstico OS | Microsoft 365 Admin, Azure Monitor, Cisco/Aruba |
Definición operativa: restaurar servicio, no solo "reparar"
Reparar un componente y restaurar un servicio no son lo mismo. Cambiar un disco averiado es una acción técnica; devolver al usuario el acceso a sus datos con integridad verificada es el objetivo real del mantenimiento correctivo IT. Esta distinción es operativamente crítica: el cierre de una intervención no puede declararse hasta que el servicio funciona correctamente, los datos están íntegros y existe un registro trazable de lo que ocurrió y cómo se resolvió.
Esto implica tres condiciones de cierre: verificación funcional (el sistema opera como antes del fallo), verificación de seguridad (no han quedado vectores de ataque abiertos durante la intervención) y documentación (registro del incidente, causa identificada y acciones ejecutadas). Sin estas tres condiciones, la intervención está incompleta, independientemente de que el componente físico haya sido sustituido.
Diferencias clave frente a mantenimiento preventivo y predictivo
El mantenimiento preventivo actúa antes del fallo: revisiones periódicas, actualizaciones programadas, limpieza de equipos y verificación de backups. El predictivo va un paso más allá y utiliza telemetría, sensores y análisis de tendencias para anticipar cuándo un componente va a fallar antes de que lo haga. El correctivo, en cambio, responde a un fallo ya producido o en curso.
Los tres enfoques son complementarios y necesarios. Un entorno IT que solo aplica correctivo acumula desgaste, coste variable elevado y riesgo creciente. Uno que solo aplica preventivo puede igualmente sufrir fallos imprevistos. La combinación eficaz —preventivo programado, predictivo basado en monitorización y correctivo bien gestionado— es la base de cualquier estrategia de continuidad robusta. En la práctica, cada incidencia correctiva bien documentada aporta información valiosa para ajustar el plan preventivo y reducir la probabilidad de recurrencia. Puedes profundizar en la parte proactiva en nuestra guía sobre mantenimiento informático preventivo para empresas.
Impacto real: downtime, riesgo, costes y experiencia de usuario
Cada hora de inactividad no planificada tiene un coste que va más allá del técnico: operaciones detenidas, plazos incumplidos, pérdida de confianza del cliente y, en sectores regulados, posibles sanciones por incumplimiento normativo. Un fallo de almacenamiento en un servidor de producción, si no se gestiona con un proceso claro de restauración y backup verificado, puede escalar de una incidencia menor a una pérdida de datos irreversible.
La experiencia de usuario también cuenta: un equipo que tarda días en resolver un problema de correo o acceso remoto genera fricción interna y erosiona la percepción del departamento IT. Por eso el mantenimiento reactivo IT no es solo una cuestión técnica; es una variable de negocio. Gestionarlo con trazabilidad, comunicación clara y tiempos definidos convierte una situación de crisis en una demostración de capacidad operativa.

Cuándo activar mantenimiento correctivo IT y cómo decidir el tipo
No todos los fallos merecen la misma respuesta. Activar una intervención de emergencia para un problema que puede contenerse con una solución temporal es tan costoso como diferir una intervención crítica que está poniendo en riesgo datos o continuidad. El criterio de decisión debe basarse en dos ejes: impacto en el negocio y urgencia técnica.
En Impulso Tecnológico, la monitorización continua de los entornos gestionados permite detectar degradaciones antes de que escalen a caída total, lo que amplía la ventana de decisión y reduce la proporción de intervenciones de emergencia. Cuando el correctivo es inevitable, el equipo multidisciplinar actúa con un criterio de priorización definido, tanto en remoto como en presencial, cubriendo clientes en España, Portugal y, de forma remota, en otros países.
- Identifica el síntoma y el alcance: ¿Afecta a un usuario, a un departamento o a toda la organización? El alcance determina la urgencia inicial.
- Evalúa el impacto en operaciones críticas: Si el sistema afectado sostiene procesos de negocio esenciales (facturación, producción, comunicaciones), la intervención es inmediata.
- Comprueba si existe contingencia viable: Si hay un sistema alternativo o workaround que mantiene la operación, la intervención puede diferirse sin riesgo adicional.
- Valora el riesgo de seguridad: Un fallo que expone datos, abre vectores de ataque o compromete la integridad del sistema siempre se trata como urgente, independientemente del impacto operativo aparente.
- Decide el tipo de correctivo: Inmediato (emergencia sin contingencia), diferido (contingencia activa, intervención en horas/días) o planificado (fallo menor, ventana de mantenimiento programada).
Disparadores en infraestructura: servidores, almacenamiento, red y endpoints
Los fallos de infraestructura física son los disparadores más habituales del mantenimiento correctivo IT. En servidores, los más frecuentes incluyen fallos de disco (especialmente en configuraciones RAID degradadas), errores de memoria RAM, sobrecalentamiento por fallo de ventilación y caídas de fuente de alimentación. En almacenamiento, la degradación silenciosa de sectores o la corrupción del sistema de archivos pueden pasar desapercibidas hasta que un proceso crítico falla.
En red, los disparadores típicos son la caída de un switch de núcleo, la pérdida de conectividad WAN, el fallo de un firewall Fortinet o un punto de acceso Aruba que deja sin cobertura a una planta entera. En endpoints, los problemas más comunes son fallos de disco en portátiles, tarjetas de red defectuosas y periféricos que dejan de funcionar en momentos críticos. La monitorización con alertas tempranas —parte del servicio gestionado de Impulso Tecnológico— reduce significativamente el tiempo entre el inicio del fallo y la detección.
Disparadores en software y servicios: corrupción, parches de emergencia y dependencias
Los fallos de software presentan una casuística diferente: a menudo no hay un componente físico roto, sino un estado inconsistente del sistema que impide su funcionamiento normal. Los disparadores más habituales incluyen la corrupción del sistema operativo tras una actualización fallida, la incompatibilidad entre un parche de seguridad y una aplicación crítica, y los fallos en cadena por dependencias rotas entre servicios.
Los parches de emergencia merecen atención especial: una vulnerabilidad crítica explotada activamente obliga a aplicar el parche de inmediato, aunque eso implique un reinicio no planificado o un periodo de pruebas acelerado. En entornos Microsoft 365 o Azure, los fallos de servicio del proveedor también generan intervenciones correctivas en la configuración local (DNS, conectores, políticas de acceso) aunque el origen esté fuera del perímetro del cliente. El criterio de decisión siempre combina impacto operativo, riesgo de seguridad y disponibilidad de una solución temporal que mantenga la operación mientras se resuelve la causa raíz.
Priorización práctica: impacto, urgencia, riesgo y ventana de intervención
Una matriz de priorización efectiva para el mantenimiento correctivo IT combina cuatro variables: impacto en el negocio (número de usuarios afectados y criticidad del proceso), urgencia técnica (velocidad de degradación o riesgo de pérdida de datos), riesgo de seguridad (exposición activa o potencial) y ventana de intervención disponible (horario, disponibilidad de técnico, piezas de repuesto).
La combinación de alto impacto y alta urgencia define la intervención inmediata. Impacto alto con urgencia media —cuando existe una contingencia activa— permite diferir la intervención con un plazo acordado. Impacto bajo con urgencia baja se gestiona como correctivo planificado dentro de la siguiente ventana de mantenimiento. Este esquema no solo mejora la gestión de tickets y SLA, sino que también genera datos valiosos: cada incidente clasificado y resuelto alimenta el historial de fallos, que a su vez informa los controles preventivos y reduce la recurrencia. Así, el correctivo se convierte en el primer eslabón de un ciclo de mejora continua, no en un evento aislado.
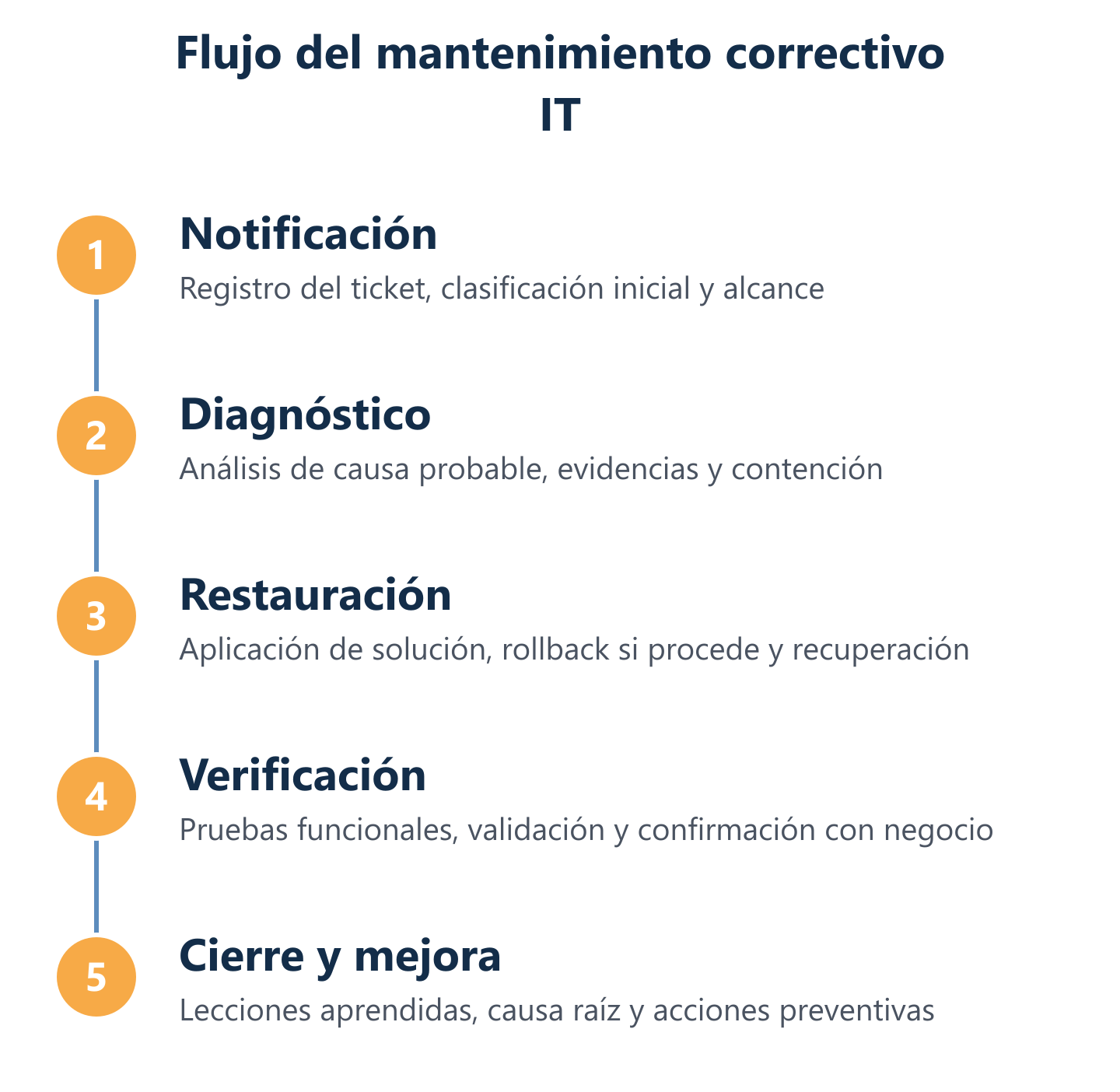
Proceso operativo y buenas prácticas para reducir el correctivo recurrente
Gestionar un incidente correctivo sin un proceso definido multiplica el tiempo de resolución y el riesgo de error. El flujo operativo recomendado cubre seis fases: detección y notificación, diagnóstico y clasificación, intervención y restauración, pruebas de verificación, aceptación por el usuario o responsable, y cierre con documentación. Cada fase tiene un responsable, un criterio de avance y un registro asociado.
En Impulso Tecnológico este flujo está integrado en el modelo de servicio gestionado: el cliente dispone de una única vía de entrada para cualquier incidencia, el equipo clasifica y actúa sin que el cliente tenga que coordinar proveedores externos, y cada intervención queda registrada en el historial del entorno. Esto permite no solo resolver el problema actual, sino identificar patrones de fallo que se trasladan al plan de mantenimiento preventivo.
- Proceso documentado: cada intervención debe generar un registro con síntoma, diagnóstico, acciones ejecutadas y verificación de restauración.
- Comunicación continua: el usuario afectado debe recibir actualizaciones de estado durante la resolución, no solo al cierre.
- Verificación funcional antes del cierre: el técnico no puede declarar el incidente resuelto sin confirmar que el servicio opera correctamente desde el lado del usuario.
- Causa raíz obligatoria: en incidentes de impacto alto, identificar la causa raíz no es opcional; es el insumo principal para evitar la recurrencia.
- Seguridad durante la intervención: cualquier acceso de emergencia a sistemas debe seguir el control de accesos habitual y quedar registrado, especialmente en entornos con requisitos GDPR.
- Retroalimentación al preventivo: los fallos recurrentes o los componentes con alta tasa de incidencia deben traducirse en acciones preventivas concretas (sustitución programada, actualización de firmware, revisión de configuración).
Flujo paso a paso: diagnóstico, restauración, pruebas y aceptación
El flujo operativo de un correctivo IT bien gestionado sigue estos pasos:
- Detección y apertura de ticket: el incidente se registra con síntoma, hora, sistema afectado y usuario o proceso impactado.
- Clasificación y prioridad: se asigna tipo (inmediato, diferido o planificado) y se notifica al responsable técnico.
- Diagnóstico: análisis del síntoma, revisión de logs, comprobación de alertas de monitorización y verificación del alcance real del fallo.
- Intervención y restauración: ejecución de la solución (sustitución de componente, rollback, restauración de backup con Veeam, reconfiguración de red).
- Pruebas de verificación: comprobación técnica de que el sistema opera correctamente y que no han aparecido efectos secundarios.
- Aceptación: confirmación por parte del usuario o responsable de que el servicio ha vuelto a la normalidad.
- Cierre y documentación: registro completo de la intervención, causa identificada y acciones ejecutadas para el historial del entorno.
Registro y aprendizaje: causa raíz, historial y alimentación del preventivo
El registro sistemático de cada incidente correctivo es la base del aprendizaje operativo. Un historial bien mantenido permite identificar componentes con alta tasa de fallo, patrones de recurrencia por entorno o por tipo de sistema, y correlaciones entre cambios recientes (actualizaciones, migraciones) y aparición de incidencias.
La causa raíz no siempre es el componente que falló: puede ser una configuración incorrecta, un proceso de actualización sin pruebas previas o un equipo que superó su vida útil sin ser reemplazado. Documentar esta distinción es lo que convierte el correctivo en aprendizaje. Las acciones derivadas —ajuste del plan preventivo, actualización de procedimientos, sustitución programada de hardware— cierran el ciclo y reducen la probabilidad de que el mismo fallo vuelva a ocurrir. En entornos gestionados por Impulso Tecnológico, este historial también facilita la toma de decisiones sobre renovación de infraestructura y la planificación de presupuesto IT. Si estás evaluando los costes de un servicio de este tipo, nuestra guía sobre presupuesto de mantenimiento informático ofrece criterios concretos.
Indicadores y trade-offs: RTO/RPO, coste variable, desgaste y recurrencia
El RTO (Recovery Time Objective) define el tiempo máximo tolerable para restaurar un servicio tras un fallo; el RPO (Recovery Point Objective) define la cantidad máxima de datos que se puede perder. Ambos parámetros deben estar definidos antes de que ocurra el incidente, no durante. Un servidor crítico sin RTO definido convierte cualquier fallo en una crisis sin criterio de resolución.
El coste variable del correctivo de emergencia es sistemáticamente más alto que el de una intervención planificada: piezas de repuesto urgentes, técnico desplazado fuera de ventana habitual y tiempo de diagnóstico bajo presión elevan el coste total. El desgaste acumulado por reparaciones repetidas sobre el mismo componente también aumenta el riesgo de fallo secundario. Por eso la métrica de recurrencia —número de incidentes del mismo tipo en un periodo— es un indicador de alerta temprana: si un componente o sistema genera más de dos correctivos en seis meses, la decisión económicamente racional es la sustitución planificada, no una tercera reparación de emergencia.
Contar con un proceso definido para el mantenimiento correctivo IT transforma la respuesta a incidentes: deja de ser una reacción improvisada y se convierte en un procedimiento controlado con criter
