
La gestión de incidencias informáticas es el proceso estructurado mediante el cual un equipo IT detecta, registra, prioriza, diagnostica y resuelve cualquier interrupción o degradación del servicio, con el objetivo de restablecer la operativa normal en el menor tiempo posible y con el menor impacto sobre el negocio.
Cuando una incidencia no se gestiona con criterio, las consecuencias se acumulan rápido: tiempos de inactividad no controlados, SLA incumplidos, pérdida de productividad y, en los peores casos, brechas de seguridad que pasan desapercibidas. El problema no suele ser la falta de técnicos, sino la ausencia de un proceso homogéneo: sin registro estandarizado, sin reglas de priorización claras y sin un flujo de escalado definido, cada incidencia se resuelve de forma diferente y el aprendizaje se pierde.
Un proceso de gestión de incidencias bien diseñado convierte esa reactividad en operación predecible: tiempos de respuesta medibles, resolución en primera intervención cuando es posible y trazabilidad completa desde el ticket hasta el cierre. El resultado es una infraestructura IT más estable, costes de soporte más controlados y usuarios que confían en el servicio.
Qué es la gestión de incidencias informáticas y por qué importa
Gestionar incidencias informáticas no es sinónimo de "apagar fuegos". Es un proceso formal con actividades, responsables, datos y métricas, orientado a un objetivo concreto: devolver el servicio a su estado normal lo antes posible, minimizando el impacto sobre usuarios y operaciones. Según el marco ITIL, una incidencia es cualquier interrupción no planificada o reducción en la calidad de un servicio IT, lo que incluye desde un equipo que no arranca hasta una caída parcial de conectividad o un fallo en la autenticación corporativa.
En Impulso Tecnológico tratamos cada incidencia como un requerimiento asignable con criterio: se resuelve en primera intervención cuando es posible y se escala a especialistas senior solo cuando la complejidad lo exige. Gracias a más de 25 años de experiencia en servicios IT gestionados, mantenemos consistencia técnica incluso en clientes con sedes distribuidas en varias provincias, combinando soporte remoto y presencial bajo protocolos homogéneos.
| Dimensión | Sin proceso estructurado | Con gestión de incidencias formal |
|---|---|---|
| Tiempo de resolución | Variable e impredecible | Medible y sujeto a SLA |
| Trazabilidad | Nula o parcial (email/teléfono) | Registro completo en sistema centralizado |
| Priorización | Por orden de llegada o urgencia percibida | Por impacto en negocio y urgencia real |
| Escalado | Ad hoc, sin criterios definidos | Funcional y jerárquico con reglas claras |
| Aprendizaje organizativo | Se pierde con cada resolución | Documentado y reutilizable en base de conocimiento |
| Coste de inactividad | Difícil de cuantificar y controlar | Reducido y cuantificable por métricas de servicio |
Definición operativa y alcance end-to-end
Operativamente, la gestión de incidencias informáticas abarca todo el ciclo de vida de una interrupción: desde el momento en que se detecta —por un usuario, por una alerta de monitorización o por un técnico— hasta que el servicio queda restaurado y el ticket se cierra con documentación completa. El objetivo central, tal como lo define el proceso de gestión de incidencias en ITIL incident management, es restablecer la operativa normal con el menor impacto posible en el negocio, dentro de los tiempos acordados en el SLA. Esto implica que el proceso no termina con la resolución técnica: incluye la validación por parte del usuario, el registro de la solución aplicada y, cuando procede, la apertura de un problema asociado para investigar la causa raíz.
Impacto en continuidad, seguridad y costes por inactividad
Cada minuto de inactividad tiene un coste directo e indirecto. El coste directo incluye la pérdida de productividad de los usuarios afectados y el tiempo del equipo técnico dedicado a la resolución no planificada. El coste indirecto abarca el impacto reputacional, el riesgo de incumplimiento regulatorio —especialmente relevante en sectores como sanidad, energía o servicios financieros— y la exposición a brechas de seguridad que pueden pasar desapercibidas si no existe un proceso de triage de incidencias que distinga una caída de red de un posible incidente de ciberseguridad. Un proceso maduro de gestión de incidencias reduce la exposición en las tres dimensiones: acorta el tiempo de restauración, identifica patrones de fallo recurrente y asegura que las incidencias con componente de seguridad reciben el tratamiento prioritario que corresponde.
Tipos de incidencias y ejemplos de escenarios reales
Las incidencias informáticas se agrupan habitualmente en cinco categorías operativas, cada una con implicaciones distintas para la priorización y el escalado:
- Hardware: fallo de disco, servidor inaccesible, equipo de usuario que no arranca. Ejemplo real: un NAS con RAID degradado en un centro logístico que compromete el acceso a datos de expediciones.
- Software: aplicación que no responde, error de actualización, corrupción de base de datos. Ejemplo: un ERP que bloquea el proceso de facturación al inicio del mes.
- Red y conectividad: caída de enlace WAN, pérdida de WiFi en planta, latencia elevada en VPN. Ejemplo: sede remota sin acceso a sistemas centrales durante una jornada operativa.
- Seguridad: alerta de endpoint, intento de acceso no autorizado, ransomware detectado. Requiere escalado inmediato y protocolo de contención diferenciado.
- Servicios en la nube: interrupción de Microsoft 365, fallo en sincronización de Azure AD, error en backup automatizado con Veeam.
Conocer la categoría desde el registro inicial acelera el diagnóstico y garantiza que la incidencia llega al técnico con las competencias adecuadas desde el primer momento, lo que es clave para cumplir los tiempos de SLA y mantener la confianza del usuario.
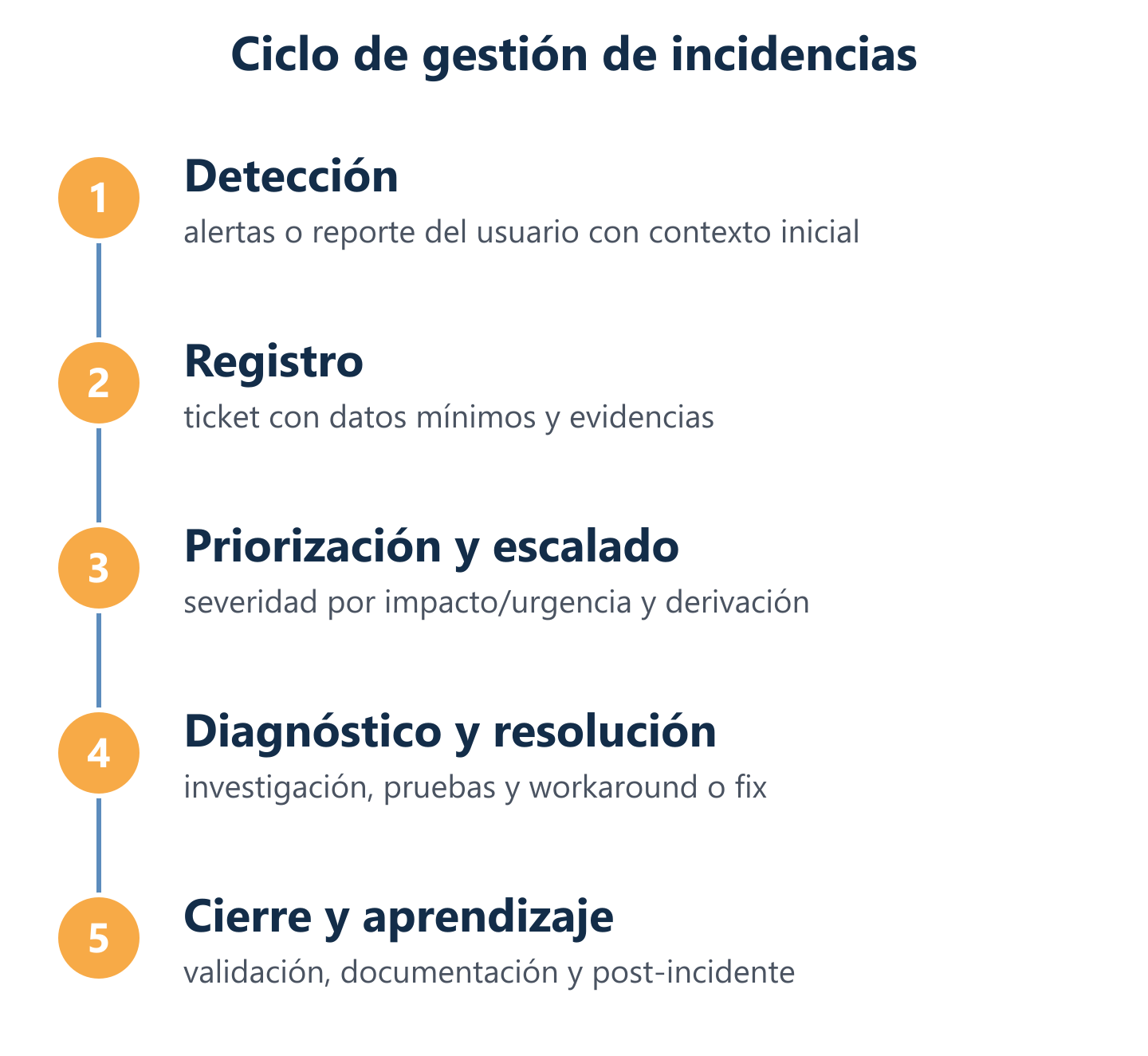
Flujo end-to-end: del ticket al cierre con trazabilidad
Un proceso de gestión de incidencias eficaz no depende del criterio individual de cada técnico, sino de un flujo estandarizado que garantiza el mismo nivel de respuesta independientemente de quién atienda el ticket. En Impulso Tecnológico, nuestro sistema centralizado de gestión de incidencias coordina soporte remoto y presencial, optimizando tiempos de desplazamiento y maximizando la tasa de resolución en primera intervención. Cada fase del proceso tiene actividades definidas, responsables asignados y entregables concretos que alimentan tanto el SLA como la base de conocimiento.
El flujo completo sigue esta secuencia:
- Detección: la incidencia se identifica por alerta de monitorización, comunicación del usuario o revisión proactiva del equipo técnico.
- Registro: se abre el ticket con todos los campos mínimos necesarios para el diagnóstico (usuario, sistema afectado, descripción, hora de inicio, impacto estimado).
- Categorización: se clasifica por tipo (hardware, software, red, seguridad, cloud) y se asigna a la cola de servicio correspondiente.
- Priorización: se calcula la prioridad combinando urgencia e impacto en negocio, determinando el tiempo máximo de respuesta y resolución según SLA.
- Diagnóstico inicial: el técnico asignado aplica el triage de incidencias, consulta la base de conocimiento y determina si puede resolverse en primera intervención o requiere escalado.
- Escalado funcional o jerárquico: si la incidencia supera la capacidad del nivel asignado, se transfiere al especialista adecuado con toda la información recogida hasta ese momento.
- Resolución: se aplica la solución, se realizan las pruebas de verificación y se comunica el resultado al usuario afectado.
- Cierre: el usuario valida la restauración del servicio, se documenta la solución aplicada y, si procede, se genera un registro de problema para análisis de causa raíz.
Registro y datos mínimos del ticket para acelerar el diagnóstico
Un ticket mal registrado multiplica el tiempo de diagnóstico. Los campos mínimos que debe contener cualquier incidencia para ser gestionable desde el primer momento son: identificador único, fecha y hora de apertura, usuario o sistema afectado, descripción detallada del síntoma (no del diagnóstico), categoría y subcategoría, impacto estimado (número de usuarios o procesos afectados), urgencia declarada, técnico asignado y estado actual. Añadir el entorno técnico relevante —sistema operativo, versión de aplicación, ubicación de la sede— reduce drásticamente el tiempo de triage de incidencias. En entornos con sedes distribuidas, como los que gestiona Impulso Tecnológico, incluir la localización geográfica permite asignar directamente al técnico más cercano con las competencias requeridas, sin pasos intermedios innecesarios.
Priorización y escalado: criterios de gravedad y asignación
La priorización por impacto y urgencia es el mecanismo que convierte el volumen de tickets en una cola ordenada y gestionable. El impacto mide el alcance de la interrupción —cuántos usuarios, procesos o sistemas críticos están afectados—, mientras que la urgencia refleja la velocidad a la que el problema se agrava si no se actúa. La combinación de ambas variables genera una prioridad (crítica, alta, media, baja) que determina el tiempo máximo de respuesta y resolución comprometido en el SLA.
El escalado funcional y jerárquico actúa cuando el nivel asignado no puede resolver en el tiempo establecido: el escalado funcional transfiere la incidencia a un técnico con mayor especialización técnica; el escalado jerárquico implica a un responsable de servicio cuando el impacto en negocio supera un umbral definido o cuando el SLA está en riesgo. Ambos tipos de escalado deben ejecutarse con toda la información del ticket ya documentada, para no perder tiempo en repetir el diagnóstico inicial.
Resolución y cierre: pruebas, comunicación y documentación
La resolución no termina cuando el técnico aplica el fix. Requiere tres pasos adicionales que determinan la calidad del cierre: verificación técnica (pruebas que confirman que el servicio funciona correctamente), validación por el usuario (confirmación explícita de que el problema está resuelto desde su perspectiva) y documentación de la solución aplicada en el ticket, con suficiente detalle para que sea reutilizable en la base de conocimiento.
El cierre con documentación y post-incidente es especialmente relevante en incidencias de severidad alta: debe incluir una nota de lecciones aprendidas, la identificación de si existe un problema subyacente que requiere análisis de causa raíz y, si procede, la apertura de un registro de cambio para evitar recurrencias. Este paso alimenta directamente la mejora continua del servicio y reduce la tasa de incidencias repetidas, un indicador clave en cualquier contrato de servicios gestionados con SLA garantizados.

Cómo implementar una operación moderna: automatización, IA y ITSM
La madurez de un proceso de gestión de incidencias informáticas se mide, entre otros factores, por cuánto trabajo manual se puede eliminar sin perder control ni trazabilidad. La automatización bien aplicada no sustituye al criterio técnico: lo libera para las incidencias que realmente lo requieren. En Impulso Tecnológico integramos seguridad y continuidad en el propio proceso de incidencias: las alertas de Sophos y Fortinet alimentan directamente el sistema de tickets, los backups gestionados con Veeam generan notificaciones automáticas ante fallos, y los entornos Microsoft 365/Azure se monitorizan de forma proactiva para detectar degradaciones antes de que el usuario las reporte.
Una implementación moderna de ITSM/Incident Management debe cumplir estos criterios operativos:
- Centralización: todos los canales de entrada (email, teléfono, portal, alerta automática) convergen en un único sistema de registro, sin tickets duplicados ni información dispersa.
- Automatización de triage: clasificación y asignación automática basada en palabras clave, categoría y reglas de negocio, reduciendo el tiempo entre detección y asignación.
- Integración con herramientas de monitorización: las alertas de infraestructura generan tickets automáticamente, eliminando la dependencia del reporte manual del usuario.
- SLA tracking en tiempo real: visibilidad del estado de cada ticket respecto a sus tiempos comprometidos, con escalado automático cuando se aproxima el límite.
- Base de conocimiento integrada: el técnico accede a soluciones documentadas de incidencias anteriores directamente desde el ticket activo.
- Reporting y métricas: paneles con MTTR (tiempo medio de resolución), volumen por categoría, tasa de resolución en primera intervención y cumplimiento de SLA por período.
- Integración con gestión de problemas y cambios: los tickets de alta severidad pueden derivar automáticamente en registros de problema o solicitudes de cambio, cerrando el ciclo ITIL incident management.
Automatización e IA con control: cuándo automatizar y cuándo escalar
La automatización de incidencias aporta mayor valor en tres momentos concretos del flujo: el triage inicial (clasificación y asignación automática), la resolución guiada de incidencias recurrentes de bajo impacto (reinicio de servicios, restablecimiento de contraseñas, liberación de espacio en disco) y la comunicación proactiva al usuario sobre el estado del ticket. La IA añade capacidad de sugerencia: analiza el historial de incidencias similares y propone soluciones al técnico antes de que inicie el diagnóstico, reduciendo el tiempo de investigación.
El límite de la automatización está en las incidencias con componente de seguridad, impacto alto o causa desconocida: ahí el criterio humano es imprescindible. Un proceso maduro define explícitamente qué tipos de incidencias pueden cerrarse de forma automatizada y cuáles requieren validación técnica, manteniendo la trazabilidad completa en ambos casos y garantizando que el aprendizaje queda registrado independientemente del canal de resolución.
Estandarización DevOps/SRE: ownership, responsabilidades y comunicación
Uno de los puntos de fallo más frecuentes en la gestión de incidencias informáticas no es técnico, sino organizativo: las "zonas grises" de responsabilidad, donde nadie sabe con certeza quién debe actuar. El modelo DevOps/SRE resuelve esto con el principio de ownership claro: quien construye o gestiona un servicio es responsable de su operación y de responder ante sus incidencias. Aplicado a entornos IT corporativos, esto implica definir para cada sistema o servicio un responsable técnico primario, un sustituto y un escalado jerárquico documentado.
La estandarización también afecta a la comunicación durante la incidencia: los stakeholders afectados deben recibir actualizaciones en intervalos definidos (no solo al cierre), con información sobre el estado, el impacto estimado y el tiempo previsto de resolución. Esta transparencia reduce la presión sobre el equipo técnico y mantiene la confianza de los usuarios, un aspecto que en Impulso Tecnológico consideramos tan importante como la resolución técnica en sí.
Criterios de decisión para una solución ITSM/Incident Management
Seleccionar una herramienta ITSM sin un checklist de requisitos previo suele derivar en implementaciones que no se adoptan. Antes de evaluar soluciones, conviene validar que cubren estas capacidades mínimas:
- Registro multicanal centralizado (portal, email, API, alerta automática) con deduplicación.
- Motor de clasificación y asignación automática configurable por reglas de negocio.
- Gestión de SLA con alertas proactivas antes del vencimiento y escalado automático.
- Base de conocimiento integrada y accesible desde el ticket activo.
- Flujos de escalado funcional y jerárquico configurables sin necesidad de desarrollo.
- Integración nativa con herramientas de monitorización, directorio activo y sistemas de comunicación (Teams, email).
- Reporting estándar con MTTR, FCR (tasa de resolución en primera intervención) y cumplimiento de SLA exportable.
- Módulos de gestión de problemas y cambios conectados al ciclo de incidencias para cerrar el proceso ITIL incident management completo.
Una solución que no cubre al menos seis de estos ocho puntos generará trabajo manual adicional que anulará parte del valor de la implementación.
Cuando el proceso de gestión de incidencias informáticas combina un flujo estandarizado, datos de registro completos, priorización basada en impacto real y automatización controlada, el resultado es una operación IT predecible y medible. Los tiempos de resolución dejan de ser una variable aleatoria para convertirse en un indicador gestionable. En Impulso Tecnológico llevamos más de 25 años ayudando a empresas a construir ese nivel de madurez operativa, desde el diseño del proceso hasta la implementación del sistema y el soporte continuo. Si quieres revisar cómo está funcionando tu gestión de incidencias actual o necesitas un modelo de servicio gestion
