
Un caso de éxito en seguridad informática empresarial es aquel en el que una organización pasa de una postura reactiva y con controles incompletos a un modelo de protección continua, con métricas demostrables: reducción del tiempo de detección, cobertura total de endpoints, copias de seguridad validadas y gobernanza de identidad activa.
La mayoría de las empresas que sufren incidentes graves no carecen de herramientas de seguridad: carecen de un modelo de gestión que las mantenga operativas, actualizadas y coordinadas. El problema real es la brecha entre tener tecnología instalada y tener seguridad gestionada. Firewalls sin reglas revisadas, endpoints sin parches aplicados, copias de seguridad que nunca se prueban y usuarios con privilegios excesivos son el origen del 80% de los incidentes documentados en entornos empresariales.
En Impulso Tecnológico abordamos este problema desde un modelo de servicio continuo: centralizamos la gestión de seguridad, aplicamos controles por capas y medimos resultados con indicadores operativos reales. El resultado es una infraestructura que no solo resiste ataques, sino que detecta, contiene y recupera con tiempos predecibles y costes controlados.
Qué significa "éxito" en seguridad informática empresarial (y cómo se mide)
El éxito en seguridad informática no se mide por el número de herramientas instaladas ni por el tamaño del presupuesto invertido. Se mide por la capacidad de la organización para detectar amenazas antes de que causen daño, contenerlas en tiempo mínimo y recuperarse sin pérdida operativa significativa. Tres preguntas concretas delimitan si un proyecto ha tenido éxito: ¿cuánto tarda la empresa en detectar un incidente?, ¿cuánto tarda en contenerlo?, ¿cuánto tarda en recuperar la operación normal?
Impulso Tecnológico traduce estos criterios a un modelo de servicio gestionado con SLA definidos, monitorización continua y mantenimiento preventivo. Apoyándonos en tecnologías de referencia como Fortinet, Sophos y Veeam, construimos una línea base medible desde el primer mes de servicio. Esto permite comparar el estado inicial con el estado posterior a la implementación de controles, y demostrar mejora con datos, no con presentaciones de diapositivas.
| Criterio de éxito | Enfoque reactivo (sin gestión) | Enfoque gestionado (MSP con SLA) |
|---|---|---|
| Tiempo de detección de incidente | Días o semanas (sin monitorización activa) | Horas o minutos (alertas automáticas y revisión continua) |
| Cobertura de endpoints protegidos | Parcial, sin inventario actualizado | Completa, con inventario y agente gestionado |
| Estado de copias de seguridad | Sin pruebas de restauración periódicas | Backups verificados con RTO y RPO definidos |
| Gobernanza de identidad | Cuentas sin revisión, privilegios acumulados | Revisión periódica, MFA activo y principio de mínimo privilegio |
| Gestión de vulnerabilidades | Parches aplicados sin calendario ni validación | Ciclo de parcheo con priorización por criticidad y verificación |
Criterios de éxito: de la prevención a la respuesta continua
El éxito medible en seguridad empresarial se construye sobre tres pilares: reducir el tiempo de detección y contención, mejorar la gobernanza de accesos y cerrar brechas conocidas antes de que sean explotadas. Según datos del sector, el tiempo medio de permanencia de un atacante en una red corporativa antes de ser detectado supera los 200 días en entornos sin monitorización activa. Reducir ese indicador a horas o días es un resultado concreto y demostrable.
La gobernanza de identidad —quién accede a qué, desde dónde y con qué nivel de privilegio— es el control que más impacto tiene en la reducción de superficie de ataque. Combinada con una respuesta continua basada en alertas y revisión de comportamiento, transforma la seguridad de un estado estático a un proceso operativo vivo. Ese es el cambio que define un caso de éxito real frente a una implementación puntual sin seguimiento.
Métricas recomendadas: RTO, RPO, MTTR, cobertura y madurez de controles
Cuatro indicadores operativos permiten medir la madurez de seguridad de forma objetiva. El RTO (Recovery Time Objective) define cuánto tiempo puede estar inactivo un sistema antes de causar daño operativo; el RPO (Recovery Point Objective) establece cuántos datos puede permitirse perder la empresa. El MTTR (Mean Time to Recover) mide el tiempo real de recuperación tras un incidente. La cobertura de controles indica qué porcentaje de endpoints, servidores y usuarios están bajo protección activa y con parches al día.
A estos se añaden dos métricas de madurez: la eficacia del ciclo de parcheo (porcentaje de vulnerabilidades críticas cerradas en menos de 30 días) y el estado de las pruebas de recuperación (frecuencia y resultado de los simulacros de restauración de backup). Sin estas pruebas documentadas, el RTO y el RPO son solo objetivos teóricos, no garantías reales de continuidad.
Errores comunes: auditorías sin ejecución, parches sin validación y IAM sin gobierno
El patrón más repetido en empresas que sufren incidentes graves es haber realizado una auditoría de seguridad sin ejecutar las recomendaciones. Los informes quedan archivados, las vulnerabilidades permanecen abiertas y la superficie de ataque no se reduce. Esto es lo que el sector denomina "seguridad de papel": cumplimiento documental sin impacto operativo real.
Otro error frecuente es aplicar parches sin validar que el sistema funciona correctamente después, lo que genera resistencia interna al parcheo y retrasos que dejan ventanas de exposición abiertas durante semanas. El tercer error crítico es la gestión de identidad sin gobierno activo: cuentas de usuarios que ya no trabajan en la empresa, privilegios acumulados sin revisión y ausencia de MFA en accesos remotos. Estos tres factores combinados son la causa directa de la mayoría de los incidentes de exfiltración de datos documentados en entornos empresariales medianos y grandes.

Caso real: diagnóstico del riesgo (identidad, endpoints y red)
Antes de implementar cualquier control, el diagnóstico determina dónde está el riesgo real y qué debe abordarse primero. En Impulso Tecnológico estructuramos este proceso en fases secuenciales que permiten pasar del inventario inicial a un plan de acción priorizado en semanas, no en meses. Al centralizar todos los servicios IT en un único proveedor, eliminamos la fragmentación de información que habitualmente impide tener una visión completa del riesgo.
El diagnóstico cubre tres dominios críticos: identidad y accesos, postura de endpoints y arquitectura de red. Cada uno genera hallazgos accionables con nivel de criticidad asignado. El resultado no es un informe para archivar, sino una lista de trabajo ordenada por impacto y esfuerzo de remediación.
- Inventario de activos: identificar todos los dispositivos, sistemas y usuarios activos, incluyendo activos no gestionados o en la sombra.
- Revisión de identidad y accesos (IAM): auditar cuentas activas, privilegios asignados, uso de MFA y segregación de roles.
- Evaluación de endpoints: comprobar cobertura de agentes de protección, estado de parches y configuraciones de hardening.
- Análisis de red: revisar segmentación, reglas de firewall, rutas de acceso remoto y puntos de exposición perimetral.
- Revisión de copias de seguridad: verificar que los backups existen, están actualizados y han sido restaurados con éxito recientemente.
- Priorización de hallazgos: clasificar cada brecha por criticidad, probabilidad de explotación e impacto en el negocio.
Inventario y exposición: qué se detecta primero y por qué
La revisión de identidad es el primer dominio que se analiza porque es el vector de entrada más explotado en incidentes empresariales. El diagnóstico de IAM comienza por enumerar todas las cuentas activas en el directorio, identificar cuáles tienen privilegios de administrador y verificar qué porcentaje de usuarios tiene MFA habilitado en accesos remotos y aplicaciones críticas. En entornos sin gobierno activo, es habitual encontrar entre un 15% y un 25% de cuentas que pertenecen a empleados que ya no están en la organización.
La segregación de roles —asegurarse de que cada usuario solo accede a lo que necesita para su función— es el segundo hallazgo más frecuente. Cuentas con privilegios acumulados a lo largo de años, sin revisión periódica, representan una superficie de ataque interna que ningún firewall puede mitigar. Detectar y corregir esto en la fase de diagnóstico es uno de los pasos con mayor retorno de seguridad por esfuerzo invertido.
Hallazgos accionables: cómo convertir evidencias en un plan priorizado
La postura de seguridad de los endpoints es el segundo dominio crítico del diagnóstico. El hardening de endpoints consiste en reducir la superficie de ataque de cada dispositivo: deshabilitar servicios innecesarios, aplicar configuraciones de seguridad base y asegurar que el agente de protección está activo y actualizado. En entornos con gestión de vulnerabilidades madura, cada endpoint tiene asignado un nivel de riesgo basado en las vulnerabilidades conocidas sin parchear.
La gestión de vulnerabilidades no es un escaneo puntual: es un ciclo continuo de detección, priorización por criticidad (CVSS), remediación y verificación. Los hallazgos del diagnóstico se convierten en un plan de trabajo ordenado: primero las vulnerabilidades críticas en sistemas expuestos a internet, luego las de alta severidad en servidores internos, y finalmente las de media y baja en estaciones de trabajo. El control de aplicaciones —qué software puede ejecutarse y qué no— completa esta capa de protección.
Validación inicial: pruebas de seguridad y criterios de aceptación
La arquitectura de red define las rutas que un atacante puede recorrer una vez dentro del perímetro. La segmentación de red —dividir la red en zonas con controles de tráfico entre ellas— es el control que más limita el movimiento lateral tras una intrusión. Un diagnóstico de red eficaz revisa si existen VLANs definidas por función, si las reglas de firewall entre segmentos son restrictivas por defecto y si los accesos remotos están protegidos con autenticación fuerte.
Los controles perimetrales con tecnologías como Fortinet permiten inspeccionar el tráfico cifrado, detectar anomalías y bloquear conexiones a dominios maliciosos conocidos. La validación inicial incluye pruebas de seguridad controladas —simulaciones de acceso no autorizado— para confirmar que los controles funcionan como se espera. Los criterios de aceptación son concretos: ningún acceso lateral entre segmentos sin autorización explícita, y ningún servicio expuesto a internet sin autenticación multifactor activa.
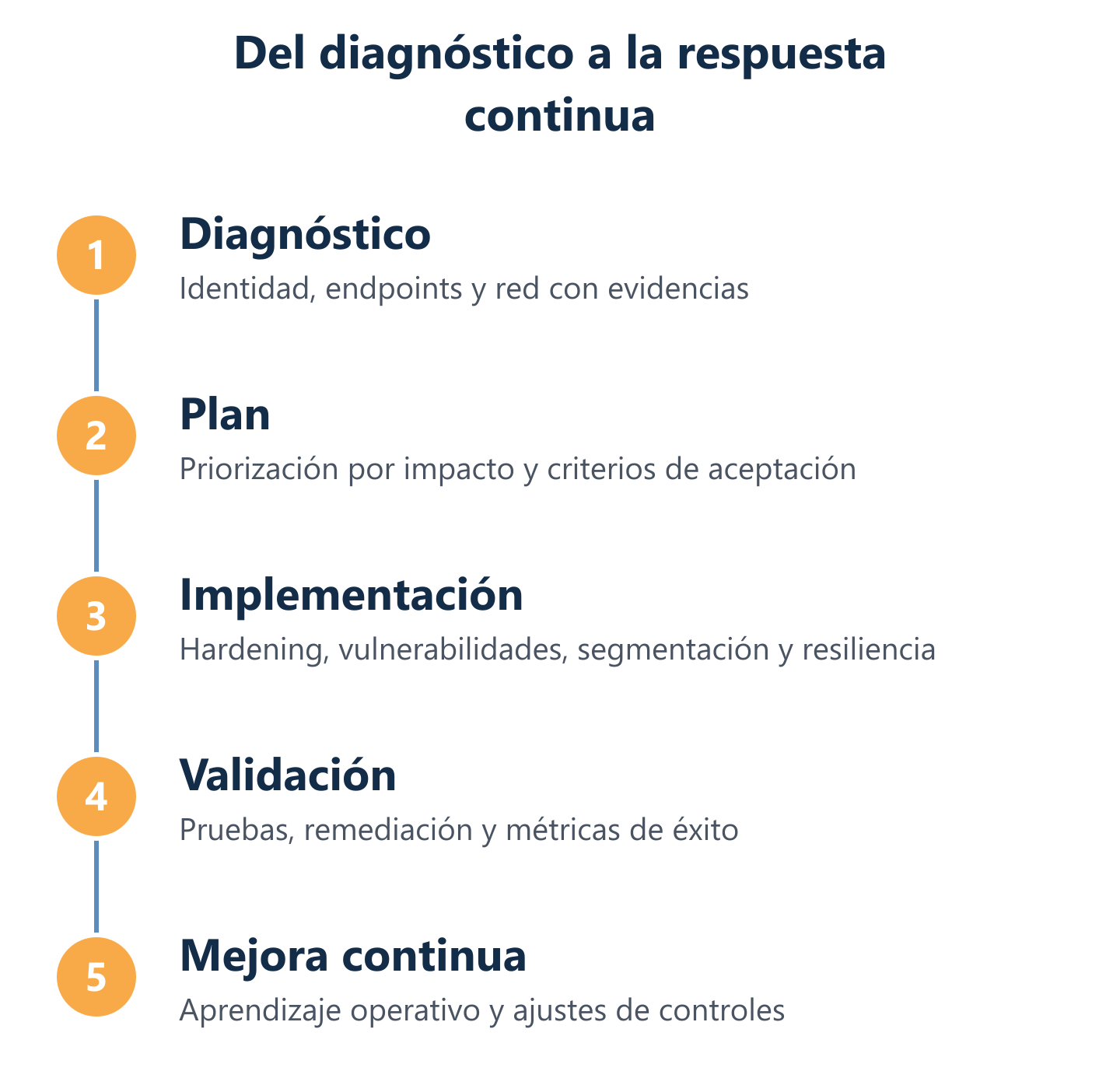
Plan de acción e implementación: de controles reactivos a respuesta continua
Una vez completado el diagnóstico, el plan de implementación traduce los hallazgos en controles operativos con responsables, plazos y criterios de verificación. La diferencia entre un proyecto de seguridad que funciona y uno que no radica en la ejecución por fases: intentar implementar todos los controles a la vez genera conflictos, resistencia interna y errores de configuración. La secuencia importa tanto como la tecnología elegida.
Impulso Tecnológico opera bajo contratos mensuales con SLA definidos, lo que permite mantener los controles activos y verificados de forma continua, sin depender de proyectos puntuales que se abandonan tras la entrega inicial. La integración de protección perimetral con Fortinet, endpoint protection con Sophos y estrategias de backup y disaster recovery con Veeam crea una arquitectura de seguridad por capas donde cada nivel compensa los límites del anterior.
- Fase 1 — Controles críticos inmediatos: MFA en accesos remotos, parches de vulnerabilidades críticas y verificación de backups.
- Fase 2 — Hardening y segmentación: configuración de endpoints, reglas de firewall por segmento y control de aplicaciones.
- Fase 3 — Monitorización y detección: despliegue de alertas, revisión de logs y definición de umbrales de respuesta.
- Fase 4 — Pruebas y validación: pentest interno, simulacros de recuperación y cierre formal de hallazgos del diagnóstico.
- Fase 5 — Respuesta continua: ciclo de revisión mensual, actualización de controles y mejora basada en incidentes reales o simulados.
Ejecución por fases: del hardening a la resiliencia con backup y recuperación
La implementación por capas sigue una lógica de impacto decreciente: primero se cierran las brechas que representan mayor riesgo de compromiso total, y luego se construye la resiliencia para cuando un control falle. El hardening de endpoints —deshabilitar puertos USB no autorizados, restringir ejecución de scripts y aplicar políticas de contraseñas fuertes— reduce drásticamente la superficie de ataque antes de que llegue cualquier amenaza.
La capa de copias de seguridad y recuperación con Veeam garantiza que, incluso ante un ransomware que supera los controles preventivos, la organización puede restaurar sistemas críticos con un RPO y RTO predefinidos y probados. Las pruebas de restauración periódicas —al menos trimestrales para sistemas críticos— son el único método válido para confirmar que el backup funciona cuando se necesita. Sin esta validación, el backup es un coste sin garantía.
Gestión de vulnerabilidades y pruebas: pentest, remediación y cierre de hallazgos
La gestión de vulnerabilidades es un proceso cíclico, no un evento puntual. El ciclo comienza con un escaneo automatizado que identifica vulnerabilidades conocidas en sistemas y aplicaciones, las prioriza por criticidad (puntuación CVSS y contexto de exposición) y genera una lista de trabajo para el equipo técnico. La remediación incluye la aplicación del parche o la mitigación alternativa cuando el parche no está disponible o implica riesgo operativo.
Las pruebas de penetración —pentest— validan que los controles implementados resisten intentos de explotación reales. A diferencia del escaneo automatizado, el pentest incluye razonamiento humano para encadenar vulnerabilidades y simular el comportamiento de un atacante con objetivos concretos. El cierre formal de hallazgos requiere verificación técnica: no basta con aplicar el parche, hay que confirmar que la vulnerabilidad ya no es explotable. Este ciclo, repetido con cadencia definida, es la base de una gestión integral de amenazas de red sostenible.
Resultados del caso: cómo medir impacto operativo y de negocio
La respuesta continua transforma la seguridad de un estado estático a un proceso operativo que aprende de cada incidente, real o simulado. Los resultados medibles de un caso de éxito incluyen: reducción del tiempo medio de detección (de días a horas), aumento de la cobertura de endpoints bajo protección activa (del inventario inicial al 100% de activos gestionados), y reducción del número de vulnerabilidades críticas sin parchear en el primer trimestre de servicio.
El impacto de negocio se traduce en menos interrupciones operativas, menor tiempo de inactividad ante incidentes y mayor confianza de clientes y auditores en la postura de seguridad de la organización. En Impulso Tecnológico, con más de 4.000 tickets IT resueltos anualmente y 476 clientes activos, el modelo de servicio gestionado demuestra que la seguridad sostenida es el resultado de procesos repetibles, no de intervenciones puntuales. Para profundizar en la base de este modelo, consulta nuestra guía de auditoría informática de seguridad y el proceso para desarrollar un plan de seguridad informática estructurado.
Transformar la postura de seguridad de una empresa no requiere el presupuesto de una gran corporación: requiere un método, tecnología adecuada y un proveedor que mantenga los controles activos y los mida con regularidad. Si buscas un caso de éxito en seguridad informática empresarial que puedas replicar, el punto de partida es siempre el mismo: diagnóstico honesto, plan priorizado por impacto y ejecución continua con validación periódica. Impulso Tecnológico acompaña ese proceso desde el primer día, con soporte presencial y remoto, tecnologías de referencia y contratos adaptados a la realidad de cada organización.
